A Practical Guide to Tecton’s Declarative Framework



In this previous blog post, we saw how treating features as code can revolutionize the feature engineering process and bridge the gap between data scientists and engineers. We introduced Tecton’s declarative framework as an abstraction to streamline feature engineering and automate the creation of production-ready feature pipelines.
This post takes a deeper dive into using a declarative framework for feature engineering. You’ll learn how using Tecton’s declarative framework during model development and experimentation, will streamline deployment of resulting feature pipelines into production.
Development and deployment of ML feature pipelines has continued to be a major bottleneck in getting models into production. Data Scientists and Data Engineers work with different languages and tools. There is a need to translate feature engineering work into data pipelines that produce the desired output. Pipelines must also be hardened for the reliability, throughput, security and governance that production applications demand.
Unified Feature Definition
Tecton’s declarative framework provides a unified way to define features using Python and SQL. This approach allows data scientists and engineers to collaborate seamlessly using a shared language and shared feature code repository.
The framework consists of four key components:
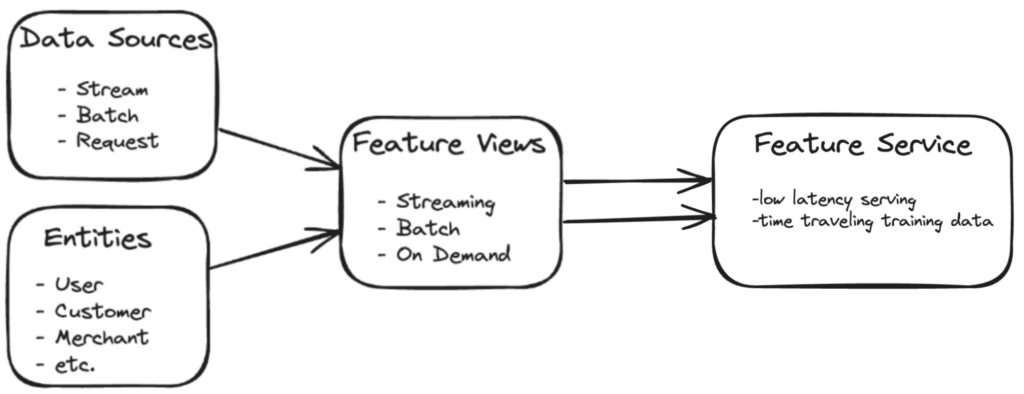
Data Sources: Tecton supports a wide range of data sources, including batch data from data warehouses or data lakes, streaming data from Kafka or Kinesis, and request-time data sources for real-time feature extraction. Data source definitions provide Tecton with all the details needed to connect and consume raw data. Data sources added to the feature code repository, can be reused to drive feature and model experimentation and the creation of any number of feature pipelines.
Entities: Entities represent the business concepts that features describe such as products, users, customers, or merchants. Defining entities involves specifying the primary key that uniquely identifies each instance. The keys are used for feature serving with fast key lookups from the online store. Entity definitions are also used to automatically build time-consistent training data that can span many feature views. Tecton’s training data retrieval SDK uses these keys and each feature’s validity time frame to build the point-in-time accurate joins that are critical for training.

Feature Views: Feature Views define the end-to-end feature pipelines, including the data sources, entities, transformations, aggregations, and compute settings. Users address different data freshness and latency requirements by using different feature view types for processing batch, stream and request time transformations. You can control which compute mode to use with options for Spark, Snowflake or Tecton’s managed compute engines. Aggregations are specified for any source column and sliding time windows. Backfills are automatically handled by just specifying a backfill time horizon. Feature Views also allow control and tuning of compute capacity and specify whether to feed the online and/or offline feature stores.

Aggregations: Tecton provides built-in support for sliding time window aggregations in both batch and stream feature views. This simplifies the creation of complex features that capture temporal patterns and statistics. In the Feature View definition, users can specify aggregation functions (e.g., sum, average, min, max) and time windows (e.g., sliding windows, tumbling windows) to be applied to the raw data. Tecton automatically generates the necessary logic to compute these aggregations efficiently, both for batch and streaming data.

Feature Services: Feature Services define the endpoints for serving features to ML models. They create feature vectors for each model by combining features from multiple Feature Views. During training, Feature Services provide time traveling feature vectors associated with specific training events. At inference time, they enable low-latency and auto-scaling feature vector retrieval. Feature services also provide feature reusability as they can retrieve any subset of features that span batch, streaming and on demand feature views.
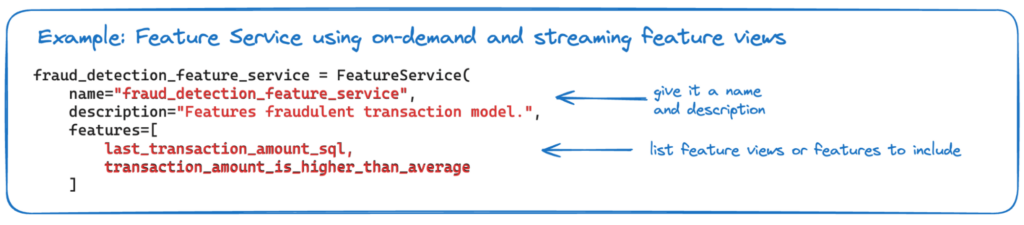
By unifying feature definitions through these components, Tecton ensures consistency and reusability across teams and projects. As a data scientist, you can easily discover and reuse existing features, reducing duplicate work and promoting collaboration. During experimentation, you can make use of the Tecton SDK to calculate new features on the fly, do feature selection and model development, all directly in the notebook environment of your choice. Once you are happy with the features, you can apply them to the Tecton platform for automated materialization.
Automating Materialization
As mentioned before, when building your own, putting feature pipelines into production requires that the data engineer do a lot of extra work. They need to provide retry logic when retryable failures occur. They need to design the pipeline to provide the throughput and data freshness that the ML model requires as input. They need to backfill the data to train and test the model. Infrastructure to drive the pipelines must be provisioned and managed. The data and the pipelines must be secured. Serving infrastructure must be deployed and monitored. Governance mechanisms must be put in place.

In contrast, when feature definitions are applied to the platform, Tecton automates the materialization of features into production-ready pipelines. The platform orchestrates the necessary infrastructure for computing and serving features based on the declarative definitions, eliminating the need for manual intervention.
This automation includes:
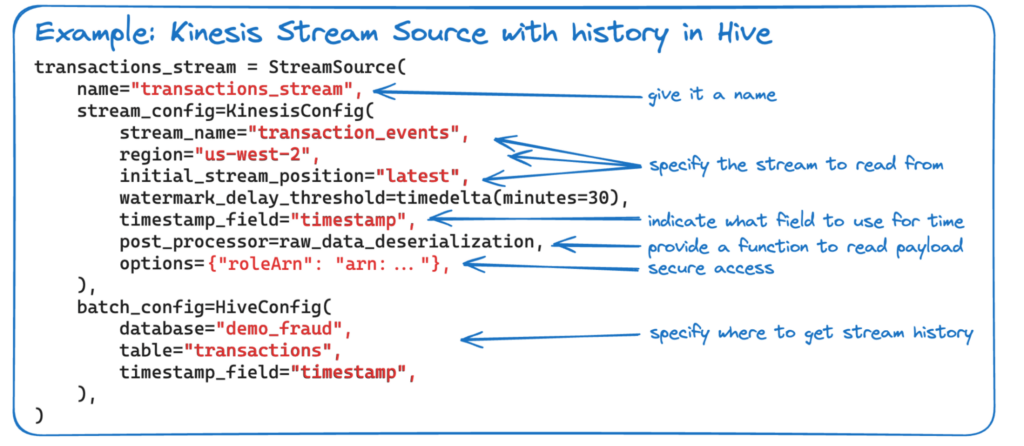
Raw Data Access: Tecton automatically sets up and manages source connections to pull batch and streaming data. For batch data, Tecton integrates with data warehouses and data lakes to efficiently extract data using parallel processing. For streaming data, Tecton connects to streaming data sources like Kafka, Kinesis or Tecton managed push endpoints to continuously consume data as it arrives.
Feature transformation: Based on the transformation code defined in the Feature Views, Tecton generates and schedules the necessary jobs to compute feature values from raw data sources. For batch data, Tecton creates batch jobs that process historical data and calculate feature values at regular intervals. Batch jobs can be scheduled to run on a daily, hourly, or custom basis, depending on the freshness requirements of the features. For streaming data, Tecton sets up streaming pipelines that continuously process incoming data and update feature values in near real-time. These jobs leverage stream processing engine that uses Spark Structured Streaming or Tecton managed compute to ensure low-latency and scalability while optimizing cost.
Aggregation Engine: Tecton has a specialized aggregation engine designed to calculate multiple time windows by using time partitioning, partial aggregation and compaction to drive processing and serving performance.
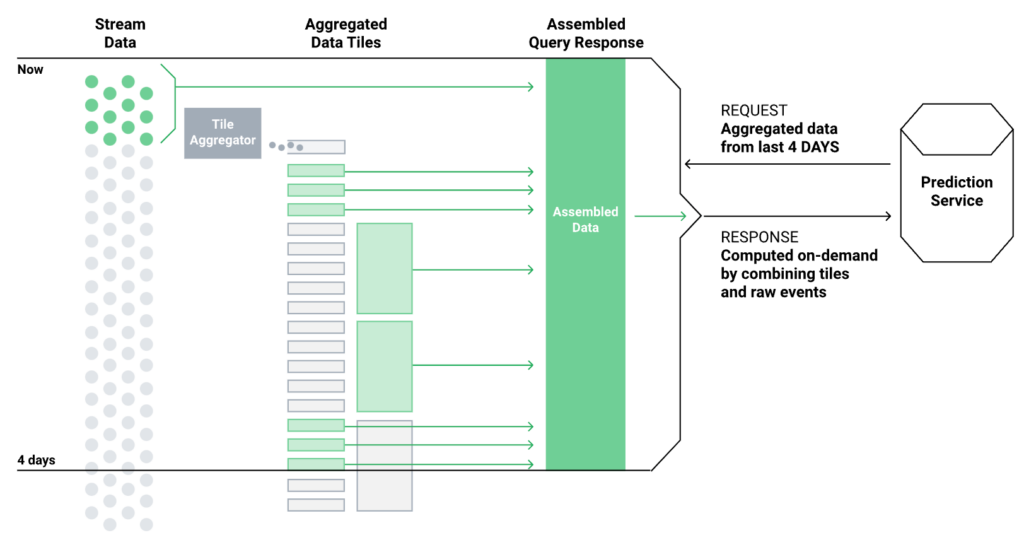
For batch data, Tecton calculates the aggregations over the specified time windows during feature transformation jobs. For streaming data, Tecton can use its own stream processing infrastructure or integrate with spark to continuously update the aggregations as new data arrives, ensuring that the feature values reflect the most recent state.
Incremental updates and backfilling: Tecton handles incremental updates and backfilling of feature values seamlessly. For batch data, Tecton consumes new data on a schedule or on-demand and incrementally processes only the new data, avoiding unnecessary recomputation of existing feature values. For streaming data, Tecton continuously updates the feature values as new data arrives, ensuring that the online feature store always has the most up-to-date values. When historical data needs to be backfilled or recomputed, Tecton automatically processes the relevant data to update the offline feature store.
Online and offline feature stores: Tecton automatically feeds the computed feature values into both online and offline feature stores. The online feature store is designed for low-latency serving and is optimized for real-time feature retrieval. It stores the latest feature values in a key/value store that can serve them with high throughput and low latency. The offline feature store, on the other hand, is designed for batch inference processing and training. It stores feature values over time and enables point-in-time joins with other datasets for model training and backtesting while optimizing storage cost.
Tecton incorporates best practices for reliability, cost optimization, and workflow orchestration, abstracting away the complexities of infrastructure management. It automatically handles retry logic, data partitioning, job scheduling, and resource allocation, enabling optimal performance and scalability for both batch and streaming workloads. This allows teams to focus on building high-quality features rather than worrying about the underlying infrastructure.
Preventing Training/Serving Skew
One of the key challenges in feature engineering is ensuring consistency between features used for training and serving. Inconsistencies can lead to model performance degradation and unreliable predictions. Tecton significantly reduces training/serving skew by using the same code for both training and serving pipelines.
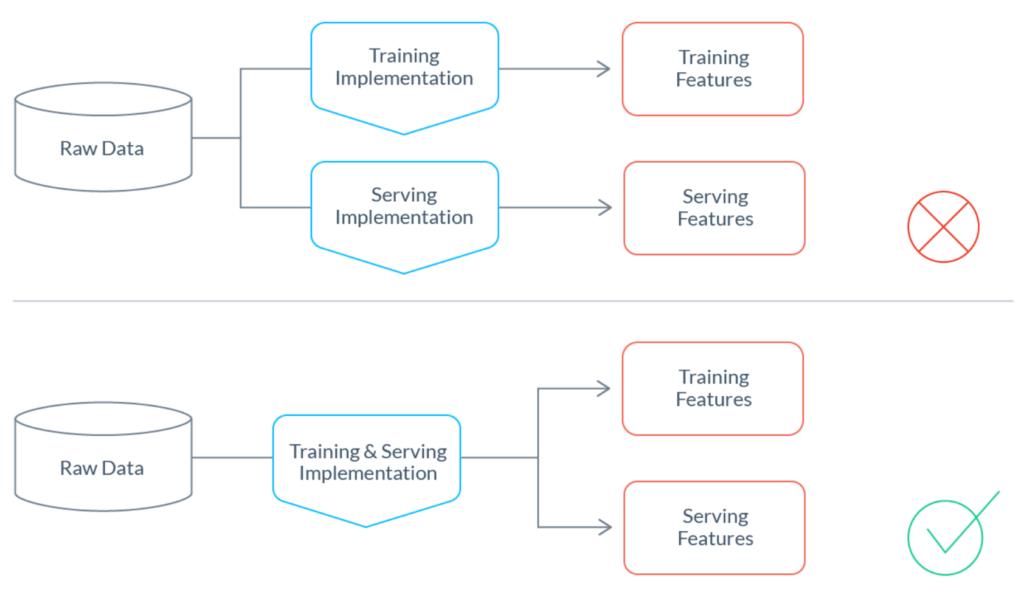
For training, Tecton provides backfills to generate accurate historic feature values. It uses the entity keys and features’ validity time frame to deliver point-in-time accurate training data. This function ensures that the features used to train models are historically accurate and consistent with the state of the data at the time of each training event. It removes the risk of data leakage and guarantees that models are trained on feature values that would have been available at the time of each event.
During inference, Tecton enables low-latency and auto-scaling feature vector retrieval through its optimized serving infrastructure. The platform automatically generates the necessary APIs and serving endpoints based on the Feature Services definitions. It handles the retrieval and aggregation of feature values from the online feature store, ensuring that the features used for inference are consistent with those used during training.
By using the same feature definitions and infrastructure for both training and serving, Tecton maintains a single source of truth for features. This approach eliminates discrepancies between training and serving data, reducing the risk of model performance degradation and increasing the reliability of predictions.
Lowering Infrastructure Costs
As more feature pipelines are deployed, infrastructure and personnel costs that drive the pipelines also tend to grow. Without pipeline optimization and governance in place, infrastructure costs can become a problem.
The Tecton Feature Platform not only streamlines feature engineering but also helps lower infrastructure costs. By abstracting away infrastructure management and optimizing resource utilization, Tecton enables organizations to reduce the total cost of ownership for their ML infrastructure.
Tecton incorporates best practices in feature pipeline engineering gathered over years of working with large scale feature platform implementations. It automatically applies best practices on workflow control, monitoring, data lineage, audit, security and governance to all the automated pipelines it creates for you.
Tecton automatically provisions and de-provisions infrastructure based on workload requirements defined across all feature views. It dynamically scales resources up or down depending on the demand for feature computation and serving. This ensures that organizations only pay for the resources they actually use, avoiding overprovisioning and unnecessary costs.
Moreover, Tecton leverages cost-effective compute options for different types of workloads. For batch workloads, it can utilize spot instances or preemptible VMs to reduce costs. For streaming workloads, it can optimize resource allocation based on the required throughput and latency. You get best practices on resource management out of the box which helps organizations optimize their infrastructure spend without compromising performance.
Tecton also allows teams to tune compute capacity based on feature pipeline needs. Data scientists and engineers can specify the desired resources for each Feature View, ensuring that critical features have sufficient compute power while less critical features can run on more cost-effective resources. This granular control over resource allocation enables organizations to make informed trade-offs between cost and performance.
By automating infrastructure management and optimizing resource utilization, Tecton helps organizations reduce the operational overhead and costs associated with feature engineering. This allows teams to focus on building high-quality features and driving business value, rather than worrying about infrastructure complexities and costs.
Conclusion
Tecton’s declarative framework allows users to control all aspects of the feature pipeline from processing raw data to serving features at low-latency. The framework drives automatic materialization, elimination of training/serving skew, and lowers infrastructure costs. By treating features as code and providing a standardized approach to feature engineering, Tecton empowers data scientists and engineers to collaborate effectively and build high-quality features at scale.
The unified feature definition through Data Sources, Entities, Feature Views, and Feature Services enables seamless collaboration and reusability across teams and projects. The automated materialization of features into production-ready pipelines eliminates manual intervention and drives performance and scalability. The reduction of training/serving skew results in more consistent and reliable predictions. And cost optimization through intelligent resource management and granular control over compute capacity helps organizations reduce their infrastructure spend.
As ML and AI continue to evolve, platforms like Tecton will be essential for organizations looking to streamline their feature engineering processes and accelerate the development and deployment of ML models. By adopting a declarative approach to feature engineering, organizations can unlock the full potential of their data and talent, driving innovation and business value in the process.


