Productionizing Embeddings: Challenges and a Path Forward





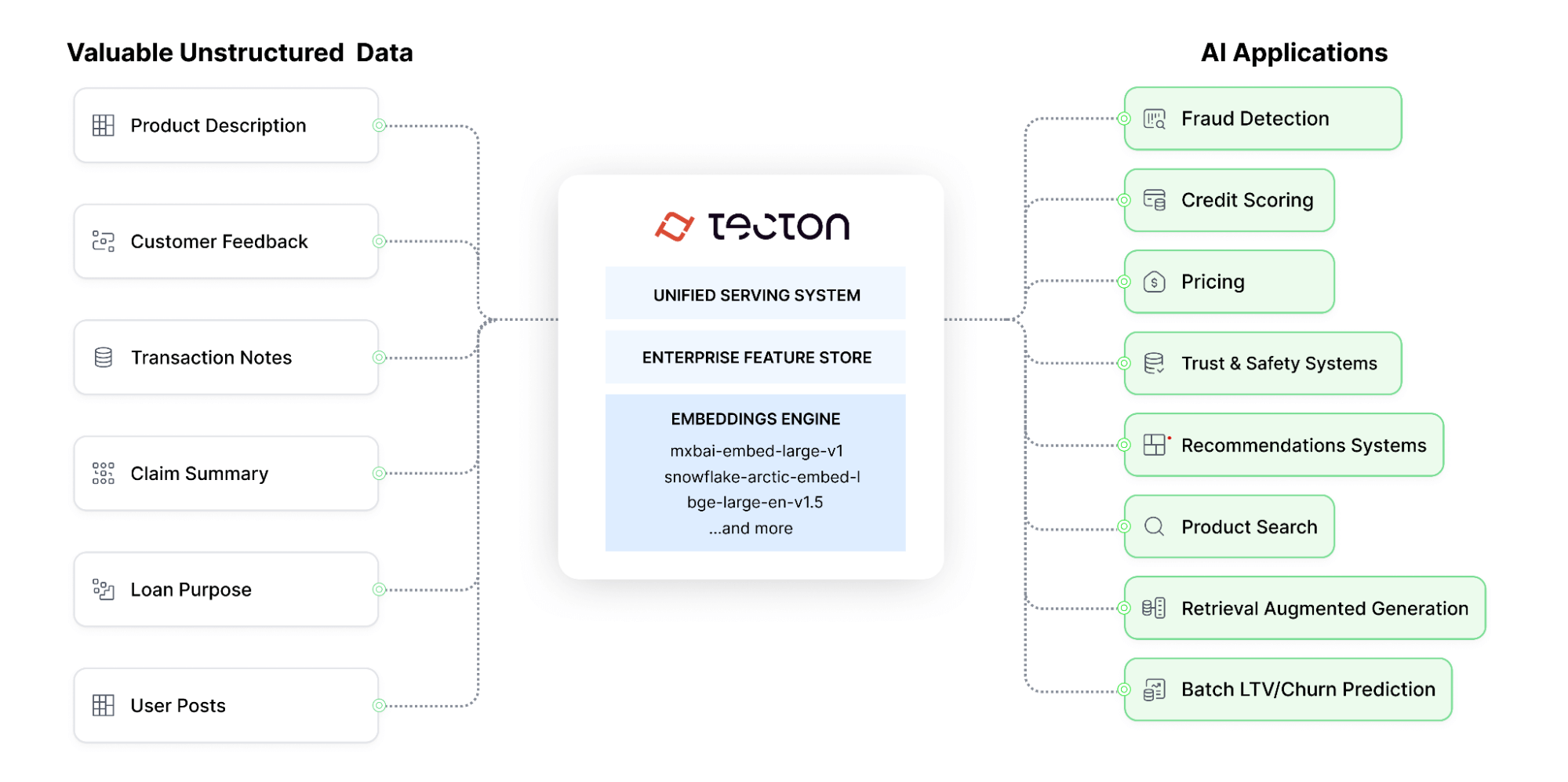
Embeddings – condensed, rich representations of unstructured data – have emerged as a transformative technique for unlocking the full potential of both predictive and generative AI.
In business-critical predictive AI applications like fraud detection and recommendation systems, embeddings enable models to identify complex patterns, leading to more accurate predictions. For generative AI, embeddings provide a semantic bridge, allowing models to leverage the contextual meaning of data to create novel, valuable content.
However, the path to productionizing embeddings at scale in business-critical AI systems is fraught with several technical hurdles. In this post, we’ll first describe the major challenges organizations face in productionizing embeddings to drive business value. We’ll then share a path to overcome these challenges using Tecton’s newly released product capability, Embeddings Generation and Serving.
Production Challenges
There are two major engineering stages needed for operationalizing embeddings at scale: Inference & Serving. Inference refers to the process of generating embeddings from input data, while Serving involves efficiently storing and retrieving these embeddings for downstream applications.
Let’s take a look at the top challenges organizations face for each of these:
Inference Challenges:
- Compute Resource Management: Large scale inference of embeddings, such as processing millions of product descriptions nightly for a recommendation system, is computationally expensive and memory intensive. Such workloads need careful provisioning, scheduling, and tuning of resources such as GPUs to ensure cost-efficient performance.
- Data Pipeline Orchestration: Orchestrating the end-to-end lifecycle of structured and unstructured data living in different sources (S3, Snowflake, BigQuery, etc.), embedding models, training and inference layer, and diverse downstream AI pipelines requires robust data engineering practices and is tedious to setup and manage.
- Training Data Generation: For retraining models, generating point-in-time accurate embeddings training data efficiently at scale without the right set of tools can be an arduous process, requiring specialized data engineering expertise.
- Ease of Experimentation & Reproducibility: Finding the optimal balance between embedding model complexity, inference performance, and infrastructure costs is a delicate dance that demands deep technical understanding and trial-and-error. Further, reproducibility of embeddings is critical for ensuring offline experiments are consistent with production. ML practitioners need tooling to quickly test, evaluate, and refine their embeddings approach while ensuring production reproducibility.
Serving Challenges:
- Efficient storage and retrieval at scale: Real-world AI applications require storing and serving tens or even hundreds of millions of embeddings. These applications need different retrieval patterns: point-based lookups by unique identifiers and vector similarity searches for nearest matches to query vectors. Achieving retrieval latencies in the tens of milliseconds while optimizing storage footprint and cost requires specialized embedding storage and retrieval architectures, which are hard to build and maintain. For instance, most-frequently accessed embeddings should be cached to ensure they’re available with minimal latency.
- Scalability: Handling irregular traffic patterns (eg. spikes or seasonality) which cause sudden increases in embeddings lookup volume without performance degradation while avoiding over-provisioning serving resources is hard to build and maintain.
Beyond these Inference and Serving challenges, there are other operational challenges around: collaboration on embeddings pipelines in a large organization, version control of embeddings, governance of embeddings, and adhering to safety standards while leveraging open-source models.
Embeddings Generation with Tecton
Over the years, Tecton has been crafted into a platform that solves the aforementioned challenges extremely well for ML features. Since embeddings are essentially model-generated features, we’ve extended Tecton’s capabilities to provide first-class support for embeddings, harnessing our expertise in effective feature management. With our new Embeddings capability, we bring Tecton’s best-in-class compute, storage, serving, and systematic approach for productionizing hand-engineered features to embeddings.
Here’s how easy it is to write production-ready embeddings pipelines with Tecton’s declarative interface:
from tecton import batch_feature_view, Embedding, RiftBatchConfig
from datetime import timedelta
@batch_feature_view(
sources=[products],
entities=[product],
features=[
Embedding(column="PRODUCT_NAME", model="Snowflake/snowflake-arctic-embed-l"),
Embedding(column="DESCRIPTION", model="Snowflake/snowflake-arctic-embed-l"),
],
mode="pandas",
batch_schedule=timedelta(days=1),
timestamp_field="TIMESTAMP",
batch_compute=RiftBatchConfig(instance_type="g5.xlarge"),
)
def product_info_embeddings(products):
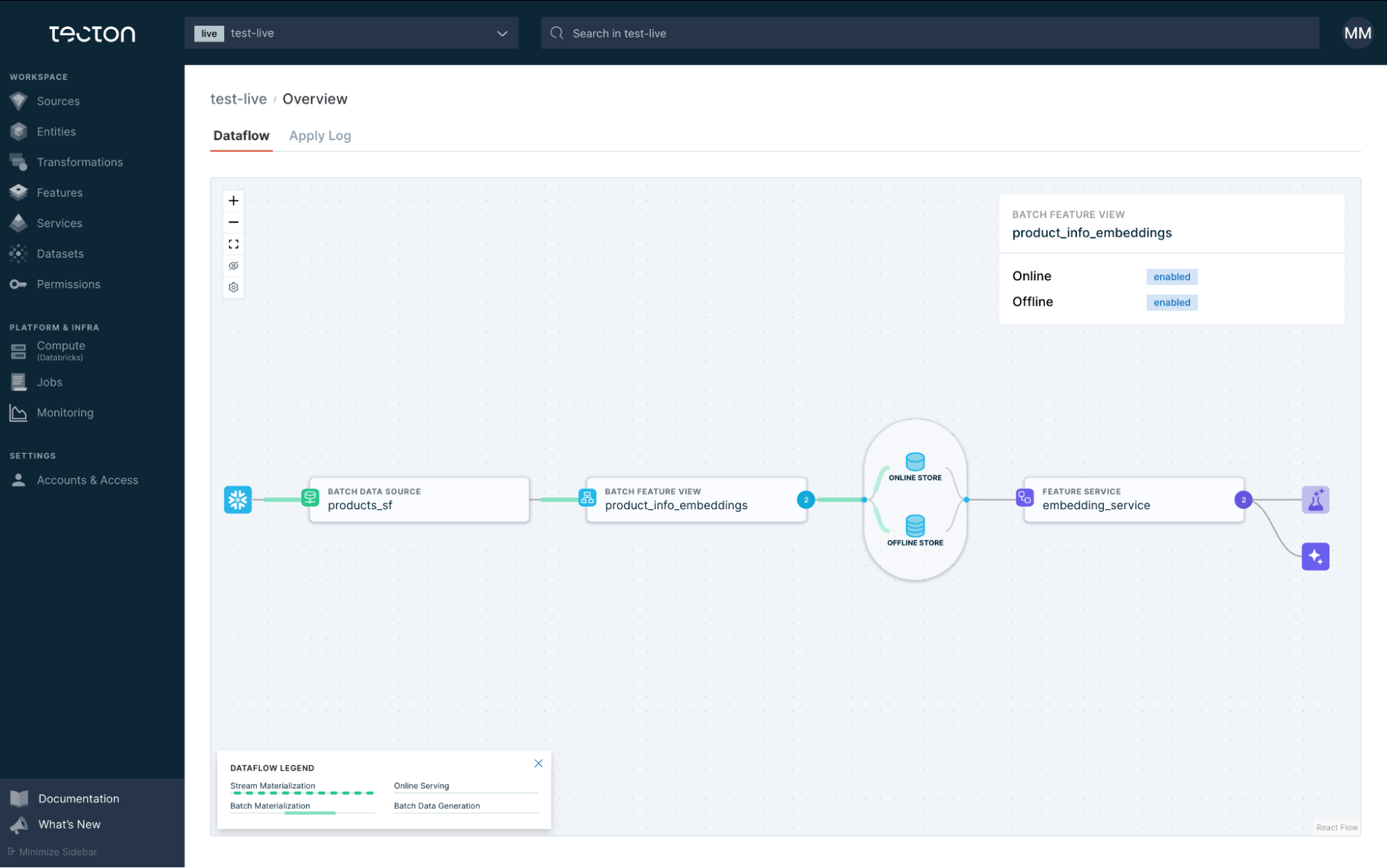
return products[["PRODUCT_ID", "PRODUCT_NAME", "DESCRIPTION", "TIMESTAMP"]]The above example shows an embeddings generation pipeline that runs daily for embedding product names and descriptions using the Snowflake/snowflake-arctic-embed-l model. Top performing open-source embeddings models are shipped out of the box with Tecton; we’ve optimized our inference for model families such as Snowflake Arctic embed, BGE, GTE, mxbai, and more. Further, the generated embeddings can be easily ingested to any vector database including Pinecone, Milvus, LanceDB, Weaviate, etc.
Here’s a Tecton screenshot showing the dataflow of the simple embeddings pipeline we defined above. This pipeline reads product data from a Snowflake data source, runs batch inference, stores the embeddings in the offline and online store for training and realtime serving through a Feature Service.
Production Inference Challenges Solved
Here’s how Tecton solves the Inference challenges mentioned above:
- Compute Resource Management: We’ve built numerous optimizations for efficient compute resource management for embeddings inference. Some of these include: dynamic batching based on sequence length, sequence length ordering per data chunk, GPU aware batch sizes that optimize throughput, column-wise inference, and a lot more.
- Data Pipeline Orchestration: Tecton’s seamless data pipeline management enables teams to connect to diverse datasources such as Snowflake or S3 or BigQuery and generate and ingest embeddings to different online and offline stores on a schedule.
- Training Data Generation: Generating point-in-time correct training data offline is a breeze by leveraging Tecton framework methods such as get_features_for_events in a notebook.
- Ease of Experimentation & Reproducibility: Experimenting with different state-of-the-art open-source models is as simple as changing a parameter to automatically run performance optimized embeddings inference. Tecton’s “features-as-code” paradigm ensures reproducibility of embeddings and guarantees online-offline consistency.
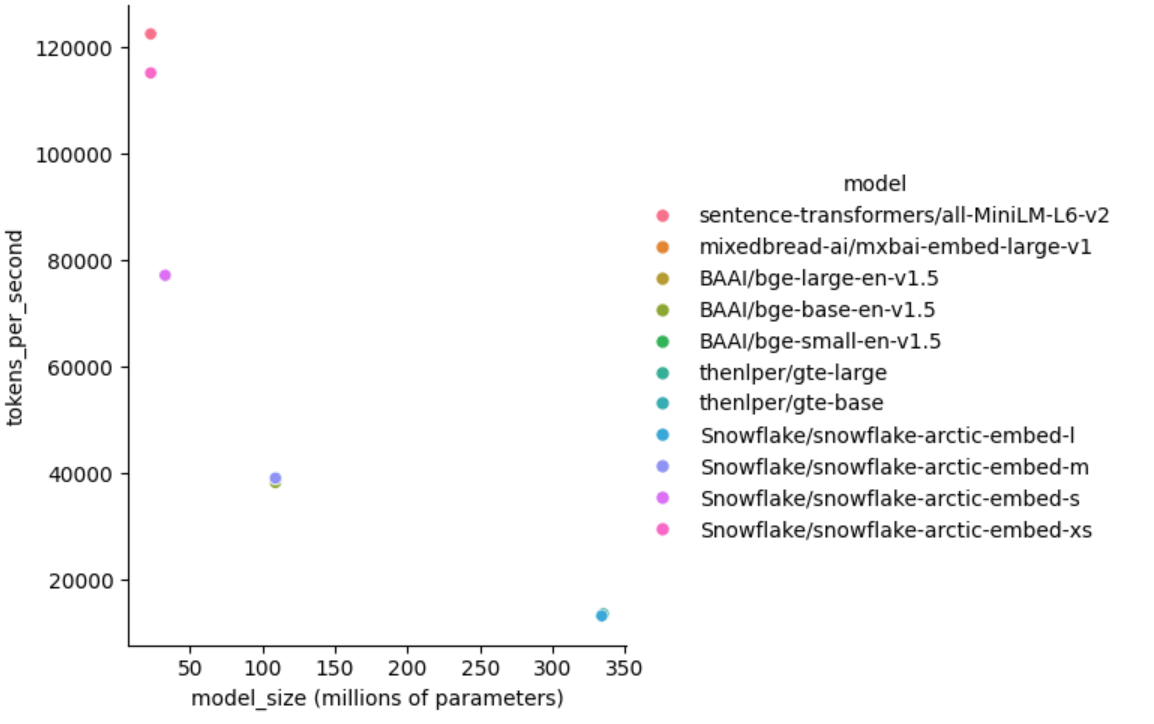
The following chart compares the inference throughput of different models using Tecton Embeddings on a single NVIDIA A10 GPU (AWS g5.xlarge), showcasing the tradeoff of model size to inference speed. This was run using the MS Marco v1.1 dataset.
Production Serving Challenges Solved
Here’s how Tecton solves the Serving challenges mentioned above:
- Efficient storage and retrieval at scale: With Tecton, modelers get the flexibility to pre-generate and serve embeddings, saving costs and reducing latency, while also allowing real-time generation when needed (eg. in Retrieval-Augmented Generation usecases). Tecton’s Serving Cache can store the most frequently accessed embeddings, ensuring minimal latency for those frequent requests. Tecton can export embeddings to any vector store, enabling organizations to leverage the unique cost-performance tradeoffs offered by various vector search solutions.
- Scalability: scaling resources to meet spiky and seasonal increases for embeddings lookup volume is effortless and cost-efficient with Feature Server Autoscaling. Further, Tecton provides critical aspects of an operationally excellent scalable embeddings serving system: best-in-class availability SLA, in-depth monitoring, and alerting.
What’s next?
At Tecton, we are laser-focused on empowering organizations to unlock the full potential of their data in mission-critical AI applications. In the months ahead, we will be rolling out significant enhancements to our Embeddings offering. Some of these include:
- More flexibility: Ability to bring in first party custom models for embeddings generation
- Better performance: Further optimizations for batch and real-time generation of embeddings
We can’t wait to see Tecton’s Embeddings capabilities power more production AI use cases—reach out to us to sign up for the private preview!