Building a High Performance Embeddings Engine at Tecton



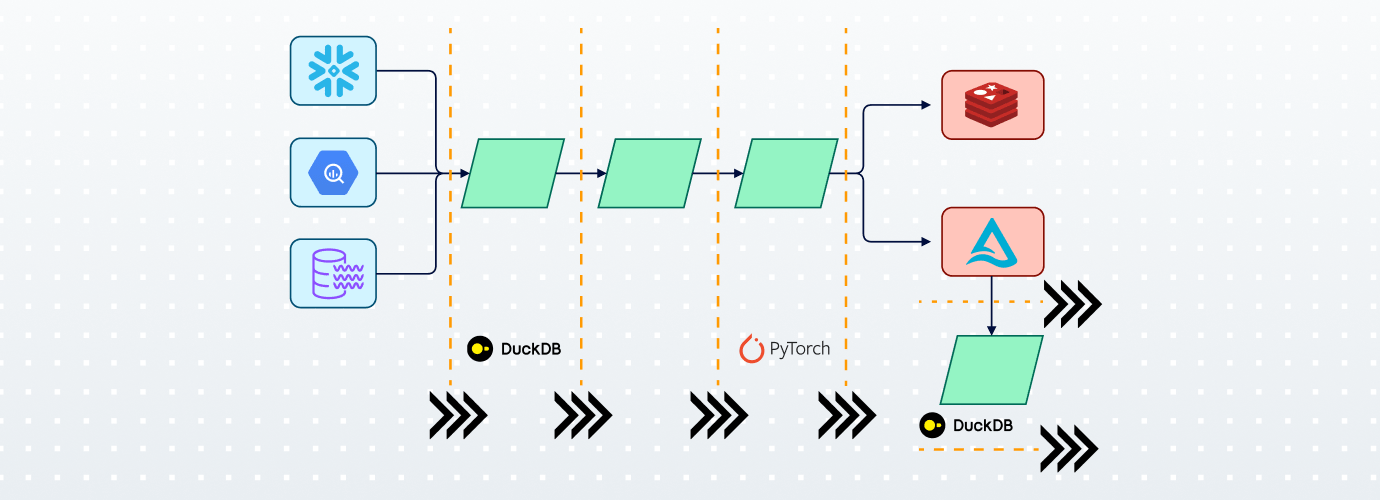
At Tecton, we’ve always been focused on enabling customers to access and use their data in machine learning applications. Historically, this has meant transforming, joining, and aggregating tabular data into features that can be used in low-latency inference and high-throughput training. However, in the past few years, there has been a shift in how the best AI applications extract signals from raw data: embeddings.
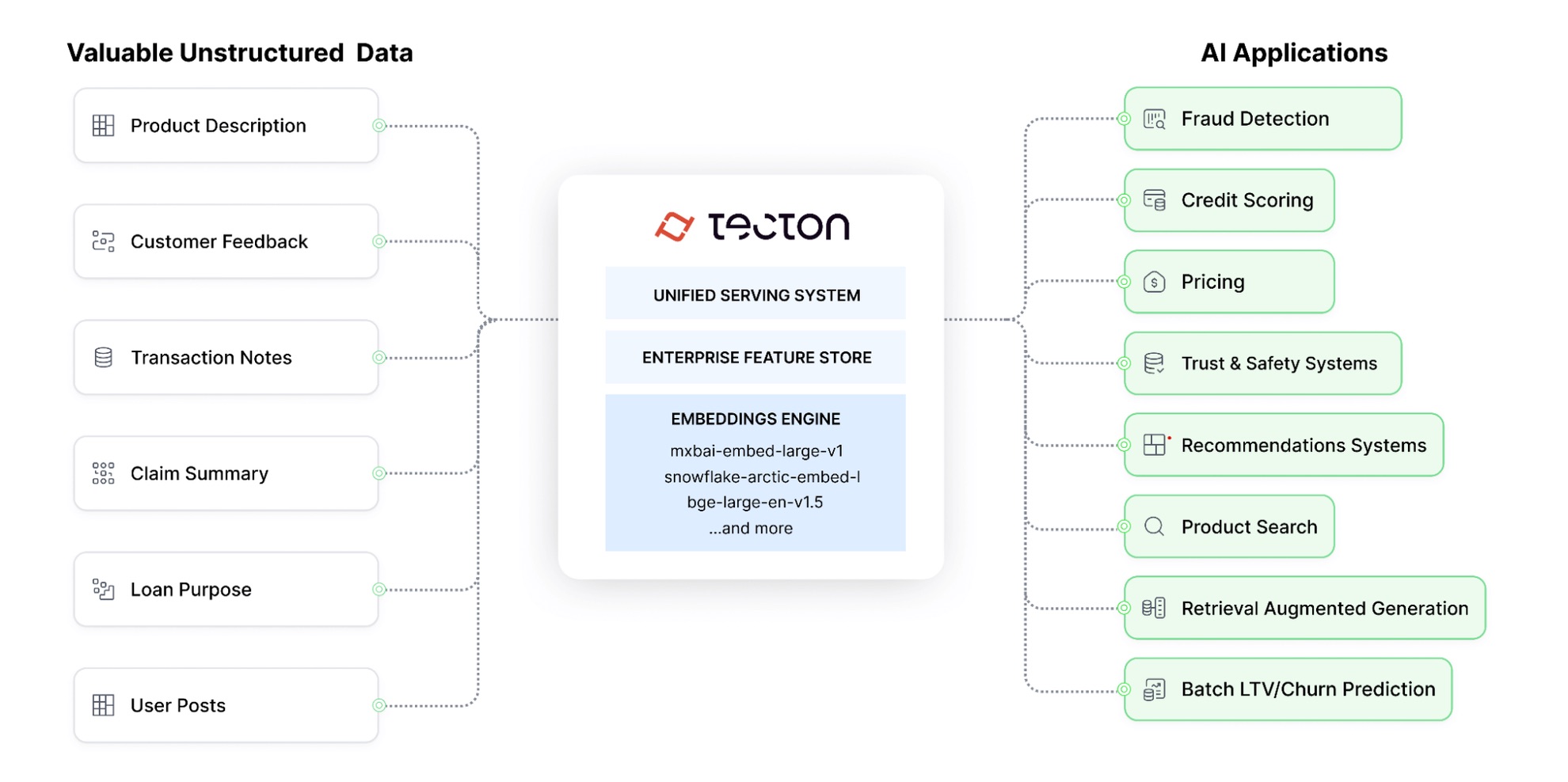
Embeddings are often used to encode unstructured data (e.g., text, images, etc.) into a numerical representation for downstream usage (e.g., input to another model or for similarity search for RAG).
We’ve built a performant Embeddings Engine to complement Tecton’s Aggregation Engine, using PyArrow, PyTorch, and Tokenizers/Transformers. Our goal was to enable customers to quickly and efficiently batch-generate text embeddings with open-source models and use them in production applications. At the scale at which our customers operate, performance is paramount.
Requirements
Tecton’s experience building our Aggregation Engine over the past few years drove our requirements for the Embedding Engine:
- Allow users to select the best embedding models to fit their use case
- Integrate into Tecton’s existing framework and compute engine, Rift, with minimal configuration
- Top-tier performance with little configuration
- distributed batch model inference on GPU instances
- automatically tuned model inference to leverage available computational resources
Engineering Design
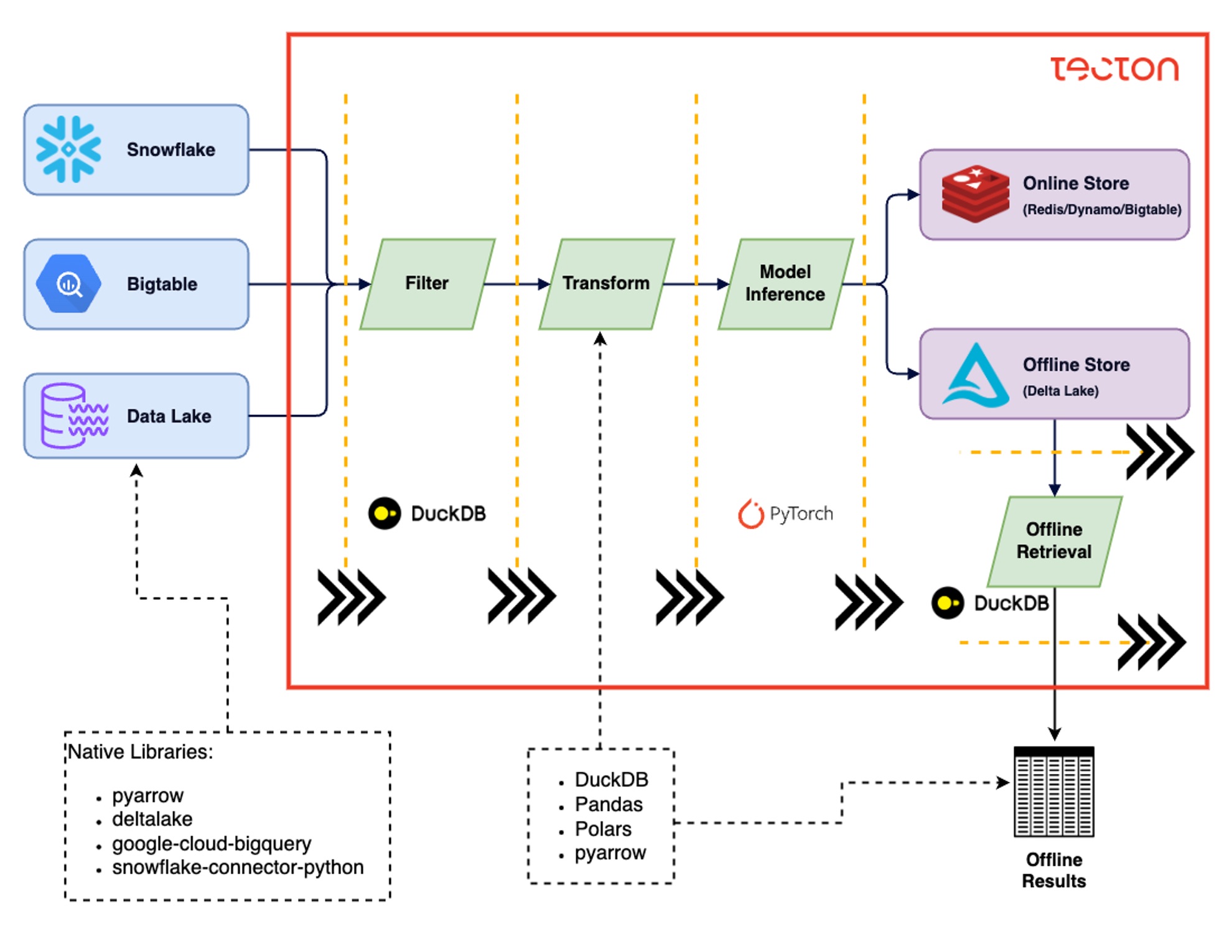
Rift is Tecton’s Python-based compute engine for batch, streaming, and real-time features.
Rift batch is executed as a multi-stage batch job using:
- DuckDB for analytical SQL, with custom extensions for some of the esoteric aggregation operations we needed
- Arrow as an interchange format between computational stages
- Warehouse SQL, Pandas, Python, etc for user-defined transformations
Rift’s support of diverse computational workloads through separate computational stages made it a great fit for model inference.
We designed an efficient multi-threaded model inference computational stage, designed to minimize GIL overhead and memory-efficient data manipulation:
- PyArrow for memory-efficient data manipulation and interchange between stages (in many cases, zero-copy!)
- Native computing libraries like PyArrow, PyTorch, and NumPy release Python’s GIL during computation. The GIL is a mutex that prevents multiple threads from executing Python bytecodes at once. Releasing it is essential for performant multi-threaded computation.
If you want to learn more about Rift, you can check out this blog post and conference talk.
Single node parallelism: Multi-processing vs Multi-threading
An early design decision we needed to make was how to parallelize across multiple GPUs within a single node. PyTorch typically recommends using multi-processing through DistributedDataParallel when training with multiple GPUs. However, this is an inference workload rather than a training workload. This means:
- No inter-GPU communication, since there is no need to all-reduce gradients and our models fit on a single GPU.
- Inputs are coming from a single process (the input
pyarrow.RecordBatchReadercontaining the output of the transformation stage) - The output of the model needs to be moved between CPU and GPU in a single process for processing (as the output
pyarrow.RecordBatchReader)
Performance Optimizations
To maximize the efficiency and scalability of our Embeddings Engine, we implemented several key performance optimizations. These enhancements focused on distributed inference, handling larger datasets, optimizing input processing, and fine-tuning batch operations. Each optimization was designed to address specific challenges we hit executing embedding inference at scale, resulting in significant improvements in throughput and resource utilization.
Distributed inference
Embeddings inference is a relatively easy workload to parallelize: it is effectively a ‘row-level’ operation on the data, it needs only one inference step per embedding, and the models fit on a single GPU.
Tecton’s backfill process already supported partitioning data temporally for bulk backfills to achieve efficient backfills for the Aggregation Engine. Tecton’s Embedding Engine continues this pattern, supporting single and multi-GPU instances. Temporally partitioned backfills enable Tecton’s Embedding Engine to distribute backfills across many concurrent jobs, scaling to thousands of GPUs, with only up-front coordination and no jobs waiting for work.
Larger than memory datasets
Tecton’s Rift engine is built on Arrow and DuckDB, which supports working with larger-than-memory datasets by spilling to disk. This same spill-to-disk support for the Embeddings Engine was a key requirement; however, we needed to build it from scratch since the model inference engine is custom-built. We implemented an output queue that wrote to disk using Arrow’s IPC format and returned an Arrow dataset reader in the computation stage.
Input Length Sorting
Text embedding models require that all inputs in the batch have the same token length. To achieve that, input batches are typically padded to the longest token length in the batch. However, strings with larger token lengths take longer to do embedding inference.
Sorting by input string length can mitigate the tradeoff between input length and inference time. Sorting ensures micro-batches used in inference use sequences of similar length, reducing extra padding.
Theoretically, the entire dataset could be sorted, but that would require materializing the input data, potentially reading many files, and shuffling the data across partitions. This would be slow for large datasets. Instead, Tecton reads from upstream data sources in large record batches and does a record batch relative sort. This allows Tecton to process record batches in a stream-like fashion, incrementally processing data.
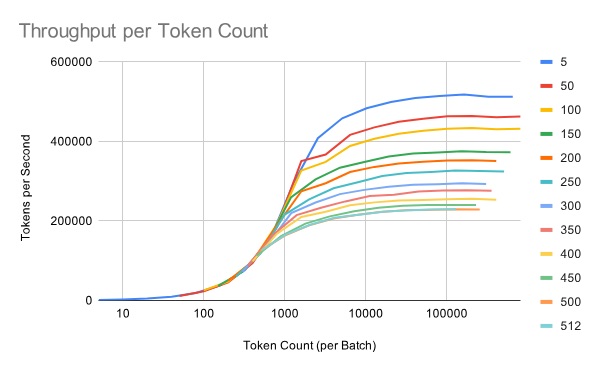
Dynamic Token Batching
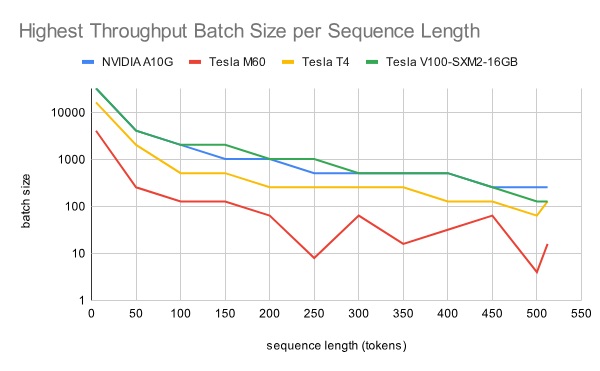
Most embedding models support up to 512 tokens. However, the batch size with the highest throughput differs across sequence lengths, complicating the choice of the batch size for a given model + GPU combination.
Below is a chart showing the batch size with the highest throughput per sequence length x GPU combination. For a given GPU, the optimal batch size could vary from >10k to ~500, depending on the sequence length.
Upon reorienting our data around token counts, a pattern emerged: There is a token count-sized batch for each sequence length, which optimizes the batch inference throughput. And there’s a token count that has close to optimal throughput across various sequence lengths!
Below is a chart showing this relationship for this workload using from an A10G GPU:
Automated Token Budget Selection
At first, we scripted the above token budget search as a grid search across multiple sequence lengths and GPUs and manually ran it across different GPUs. However, we wanted to streamline this approach to improve our ability to support new models.
The updated approach does the following:
- measured the CUDA peak memory usage when loading the embedding model and passing a batch of data through the model
- estimate the per-token GPU memory requirements
- extrapolate an ideal token budget that leverages a sufficiently large portion of the GPU
Since this new token budget selection approach runs in seconds, it is run automatically as part of the model inference stage.
Cuda OOM Batch Splitting
During large-scale performance tests, occasional CUDA OOMs were observed. After a couple of retries of that micro-batch, the job would fail, leading to wasted computing time due to retries. Often, these OOMs were associated with errors like this:
Tried to allocate 7.65 GiB. GPU 2 has a total capacity of 21.96 GiB of which 7.28 GiB is free. Including non-PyTorch memory, this process has 14.68 GiB memory in use. Of the allocated memory 9.79 GiB is allocated by PyTorch, and 4.67 GiB is reserved by PyTorch but unallocated.We devised a quick solution to automatically split batches in two if an OOM occurred. Previous token budget estimation showed that the GPU could generally fit the whole batch; however, the OOM occurred due to GPU memory fragmentation. Splitting the batch in half allowed the workload to execute with batches that the PyTorch CUDA allocator could handle. In the future, we plan to explore adjusting PyTorch’s CUDA allocator default settings to avoid these OOMs.
Results
Our batch inference system is auto-tuned to the local hardware, so adding new embedding models requires no manual tuning by our team. This means we can easily adopt new OSS models as they’re released and customers can eventually bring their own models.
The result beat both our expectations and our customers’. Tecton’s Embeddings Engine achieved an average of 100k embeddings per second across the distributed inference jobs for bulk backfill using the all-MiniLM-L6-v2 model on g6.2xlarge instances (NVIDIA L4 GPU).
Cuda OOM batch splitting dramatically improved the inference job reliability, seamlessly retrying just that single micro-batch rather than failing the whole job.
Future Performance Optimizations
Dynamic batching improvements
Our dynamic batching approach greedily adds all items into the micro-batch that can fit into GPU memory. However, this is not ideal in highly varied data, when this greedy approach leads to a sizable in-batch variance in the token length. We want to minimize this variance to avoid over-padding sequences.
Multi-node compute jobs
Running single-node job instances has yet to hit the performance limits on the individual task workloads we’ve worked with. We have leveraged faster GPUs like the L4 GPU, which recently was GA on AWS via the g6 instance type. We also built support for multi-GPU inference within a single node (supporting up to 8 GPUs executing concurrently).
However, as the workloads and models our users use grow, we expect to build support for distributing the inference workload across multiple instances, even for a single materialization period (i.e., just the incremental new data from the day).
Various Model Execution Optimizations
There are some more optimizations that we have yet to explore:
- Tuning PyTorch’s CUDA allocation patterns
- Leveraging model compilers like
torch.compileor TensorRT - Mixed precision and quantization
- So far, our optimizations have focused on improving performance without lowering model quality. Approaches like mixed precision and quantization degrade model quality but may be acceptable for some applications.
Data Processing Optimizations
The interchange formats between compute stages are Arrow-native; however, much of the model inference processing uses PyTorch + tokenizers. This leads to several memory copies to interchange between data formats, tokenize our data, pad input sequences, etc. Although we’ve done our best to minimize this, there is room for further improvement.
What’s next?
In the months ahead, we will be rolling out significant enhancements to our Embeddings offering. Some of these include:
- More flexibility: Ability to leverage hosted API models and first-party custom models for embedding generation
- Better performance: Further optimizations for batch and real-time generation of embeddings
If working on these problems excites you, please check out our careers page!