GenAI Engineering Horror Stories (And How to Avoid Them)



Who needs a haunted house to get some thrills, when you’re an engineer trying to build a useful AI-powered app?
Predictive machine learning already has its share of engineering challenges to begin with. Now generative AI use cases add to the challenge with a whole new set of horrifying technical hurdles, from hallucinations to complex manual workflows.
Here are some scary scenarios your AI team might encounter as you’re putting an LLM-powered app into production – and how you can avoid being next.
Your LLM hallucinates and your business is on the hook for an expensive chat response.
Sometimes your LLM sees things that aren’t there, and we’re not talking about ghosts. LLMs will often output generic or false information, due to gaps in its training and the inherent randomness of generated text.
And it’s a common occurrence: Chatbots can hallucinate more than a quarter of the time. When one attorney used ChatGPT to conduct legal research, the chatbot cited cases that don’t exist (and insisted they were real). Air Canada’s chatbot incorrectly promised a discount to a traveler, and the airline was held liable. So it’s no wonder hallucinations are a top concern for GenAI apps – especially the ones in production, with customer-facing implications.
How to avoid it: Retrieval-augmented generation (RAG) is the current industry standard for improving an LLM’s responses with more relevant information. When the app generates a response, it can reference a knowledge base that you provide, making the response more accurate and specific to your business domain.
But will RAG prevent other horror stories? Read on…
You decide to implement RAG – but it takes a huge amount of complex manual work as you scale.
A RAG system is difficult to build and maintain, especially as your use cases grow more advanced. You need to transform unstructured documents into embeddings, index the embeddings and store them in a vector database, implement a retrieval mechanism (usually semantic search), implement prompt engineering techniques…and so on.
And the challenges compound as you scale. You don’t add a knowledge source once and call it a day. Maintaining data freshness is a constant battle, requiring regular updates to your search index. And as you refine and update prompts, managing versions and systematically testing their performance becomes increasingly complex.
How to avoid this: There are different ways to implement RAG, so choose the framework that will allow for multiple data sources, flexible experimentation and automation. Using Tecton’s declarative framework, you can automate RAG components like embeddings generation. You can also manage prompts as code, allowing for version control and easier iteration as your RAG needs evolve.
After getting your RAG system up and running, the app still isn’t personalized enough to be helpful.
Here you are, following best practices and implementing RAG. Your LLM is finally generating more relevant responses using the domain knowledge in your vector DB. But after all that, it still doesn’t have enough information for the use case you’re building – like a customer support chatbot that can provide help based on the customer’s information.
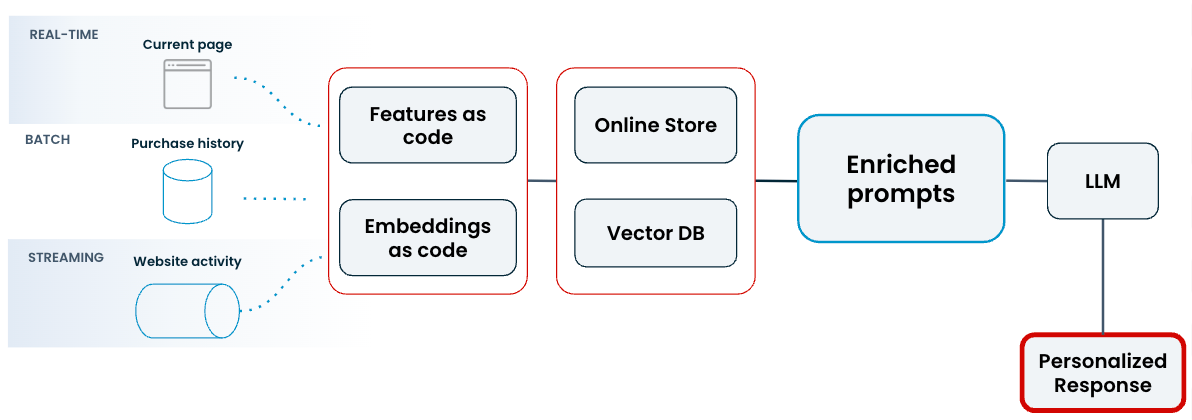
That’s because traditional RAG is an incomplete solution for production use cases that call for more personalized, up-to-date responses. Important context like a user profile, recent purchases, and real-time transactions all come from structured data sources.
How to avoid it: Enrich your LLM prompts with the full range of data sources, including structured context and fresh, real-time features. With Tecton, you can provide your system prompt with context that comes from feature pipelines and real-time sources.
You give your system prompt all of the data you’ve got, and your LLM is suffering from information overload.
You can’t always put everything you know into the system prompt. A data-heavy system prompt can introduce irrelevant context and be more distracting to the LLM. It adds latency, slowing down the system and driving up compute costs as the model processes all of the context. And for large datasets or knowledge bases, you can’t fit all the possible needed information into a single prompt.
Prompts are also pre-determined, before the conversation. You provide the context beforehand, with information that will be generally applicable for the LLM in responding to the situation. But for more interactive, dynamic responses, you’ll want the LLM to be able to retrieve additional information as needed depending on the conversation.
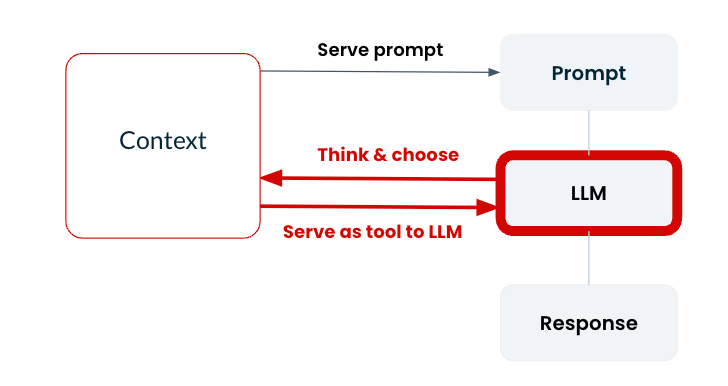
How to avoid it: Build an agentic workflow using tools. There are essentially two ways to provide context to your LLM: by putting information into the system prompt ahead of time, and by empowering an LLM agent to choose which information is needed at the time of the query.
The latter is enabled with tools. With Tecton, you can provide both knowledge and features as tools to an LLM agent, so it can access relevant data on demand. For instance, a restaurant recommendation app might query the feature last_5_visits when a user asks for restaurants they haven’t recently visited.
Build GenAI apps the smart way, not the scary way.
Sometimes when you watch a horror movie, you wonder why the characters aren’t being smarter when they’re trying to get out of a bad situation. Don’t go into the sketchy house! Use the getaway car!
In the same way, engineering teams building GenAI apps are often struggling through complex technical hurdles, when there’s a smarter solution available. Think of Tecton as your getaway car: it’s fast, reliable, and designed to get you out of tricky situations. It handles the heavy lifting of data engineering, so you can escape the monsters of inaccuracy, generic responses, inefficiency and technical debt.
With Tecton, you’re not on the run from the next engineering problem lurking around the corner – you’re speeding ahead to successful GenAI deployment.
If you’re ready to build smarter GenAI apps, watch our on-demand session that dives into some of the strategies mentioned in this blog, including enriched prompts and features as tools.