Introducing Rift: Tecton’s Compute Engine




In this article, we introduce Rift, Tecton’s efficient and scalable compute engine purpose-built for feature engineering workloads. We built Rift because other compute options were too inflexible, heavy, and slow for the problems we needed to solve. In this post we’ll cover the need for Rift, industry trends, Rift’s design principles, and system architecture, which heavily uses Arrow, DuckDB, and Ray. Rift was released to Public Preview in mid-2024 and will reach General Availability later this year.
Compute: the backbone of Tecton
Tecton’s goal is to enable teams to build AI applications in production. The idea to build a data platform for AI — the idea to build Tecton — spawned from a key problem: data is the hardest part of getting AI into production.
Tecton orchestrates data and compute across development and production environments by managing feature pipelines that read and transform data from many sources and write to multiple storage layers. It also supports complex multi-stage compute graphs that enable high-value use cases such as transaction fraud detection and account takeover prevention. We set out to build Tecton based on the Feature Store concept. Despite the term “store”, we quickly determined that an efficient, performant compute engine would be the backbone of Tecton.
Increasing complexity across platforms and clouds
Early on, Tecton delegated the compute to external platforms. First, we integrated with the Spark ecosystem by partnering with Databricks and AWS EMR, and later expanded to data warehouses starting with Snowflake. These compute engines were powerful, but over time we spent disproportionately high effort on contorting them to fit workloads they were never meant to handle. In a sense, Tecton was a car that allowed drivers to bring their engine of choice. Tecton’s UX became inconsistent depending on compute platform or environment due to a lack of a single portable compute engine that worked across environments and platforms.
Over time, Tecton’s integration with Spark became increasingly complex. It needed to support a growing graph of data flows that supported requirements like low-latency storage layers with varying APIs, writing to object stores, stream ingestion, real-time transformations, and downstream computations. With Spark, JVM overhead with distributed workers also meant jobs were slow to start and difficult to debug. This was an overkill for small jobs (more on that in the next section). Lastly, as we moved from just AWS to supporting another cloud, Google Cloud, we navigated a new dimension of discrepancies between cloud resources across AWS EMR and Google Dataproc and Databricks quirks across clouds.
In parallel with Tecton’s growth, the data ecosystem has exploded with innovations which have unlocked capabilities that were a pipedream a few years ago. We needed a better compute engine, and the timing was right to build something in-house.
Industry Trends
Big data is dead… as we knew it
We started building Tecton in 2019 with a dependency on the Spark and Hadoop ecosystem, these tools were and largely still are the de facto standard for “big data”. Early customer conversations were predicated on most use cases involving proverbial big data. Since then, a few things have changed that challenged this initial decision and some of our assumptions.
The developments described in the next section made it enticing and, in retrospect, obvious to build a new compute engine optimized for single-node execution to avoid the many complexities with distributed query engines. We are not the only ones noticing this.
The threshold of “big machine” increased faster than “big data”
If big data is interpreted as datasets too large to be processed in-memory on one machine, this threshold can be reasonably measured over time using the largest machine available to apply to your problem. Here is a plot of the largest RAM capacity available among EC2 instances by date of general availability:
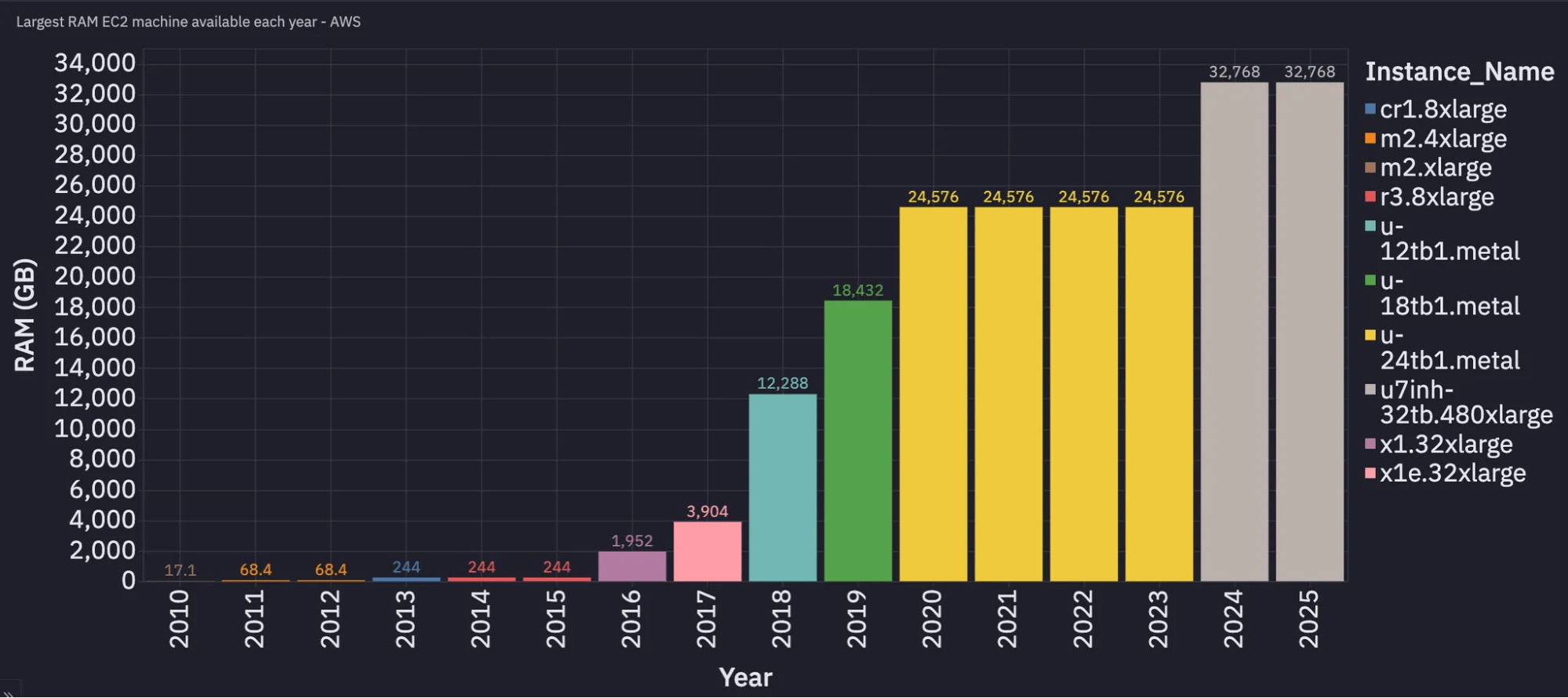
This is unsurprising considering Moore’s Law, however most datasets we encounter at Tecton have not grown at the same rate since 2019, meaning the prevalence of datasets larger than the largest machines available has decreased considerably.
Single-node queries are cool again
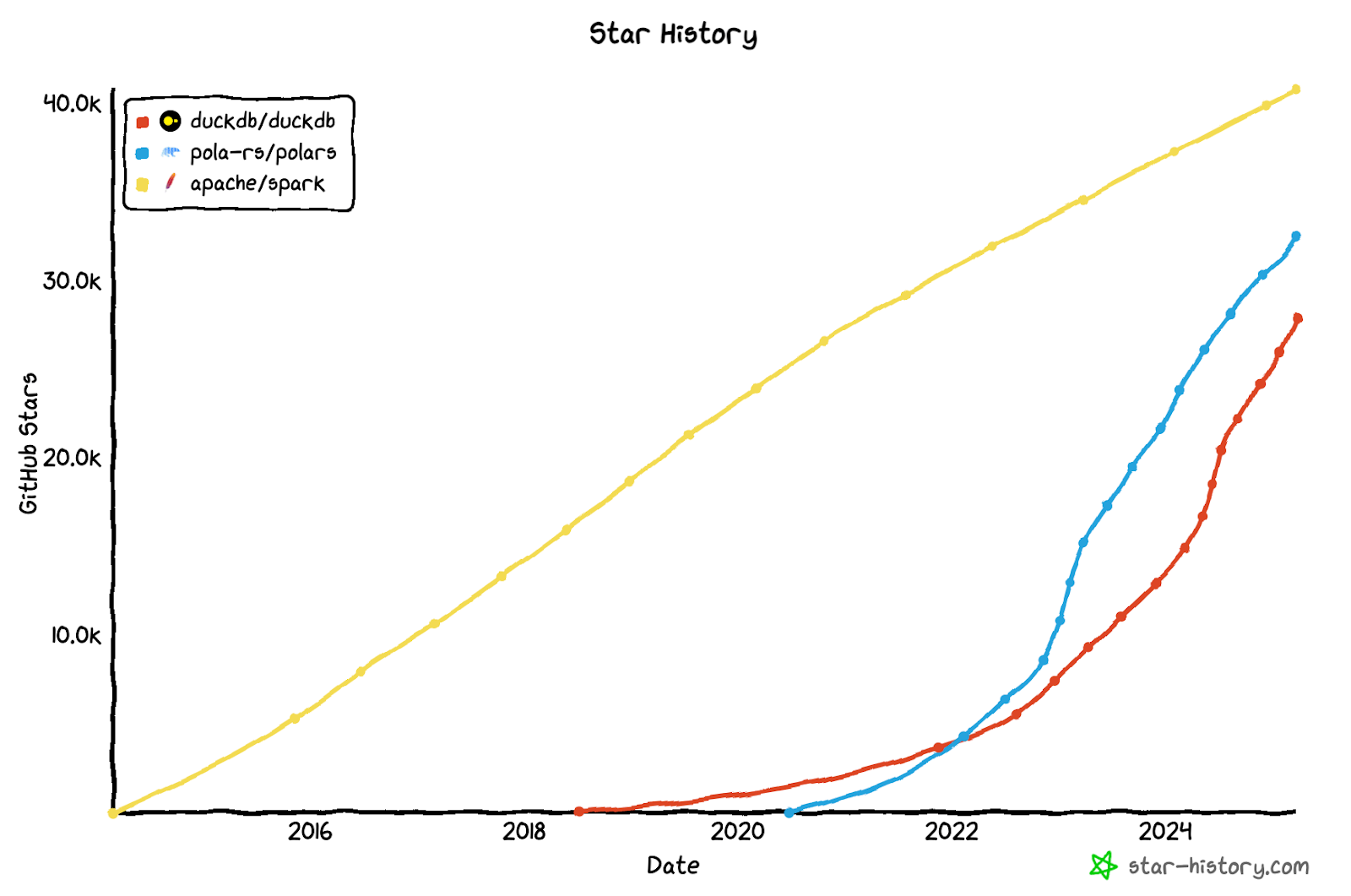
In parallel, we’re witnessing a renaissance in tools available for analytical queries on large datasets on a single node. The plot below shows the rapid rise in popularity, measured by GitHub stars, of DuckDB and Polars against the incumbent, Spark. Single-node systems offer compelling advantages: they eliminate network shuffle operations and communication overhead, provide better cost efficiency through reduced infrastructure requirements, enable more straightforward debugging, and simplify operations with fewer potential points of failure. As data practitioners increasingly seek to balance performance with simplicity, these single-node analytical engines demonstrate that distributed computing isn’t always necessary to achieve impressive results at scale.
Storage and Compute separation
Another major shift in the big data ecosystem has been the widespread adoption of the separation of compute and storage. This architectural pattern decouples data storage from data processing, allowing each to scale independently. Cloud object storage services like AWS S3, Azure Blob Storage, and Google Cloud Storage have become the de facto data lakes, storing vast amounts of data in open file formats like Parquet, Avro, or ORC.
This separation enables organizations to use multiple processing engines on the same dataset without data duplication or migration. Data scientists can analyze S3 data using DuckDB for exploration, while data engineers use Spark for production pipelines, and ML engineers leverage Rift for feature engineering—all with on-demand computing resources that scale based on workload requirements while minimizing costs and maintaining technology flexibility.
Guiding Principles for Rift
📌 Note: This post focuses on Rift’s batch compute engine. Rift components are also used in Tecton’s streaming and realtime compute pipelines, which are out of scope for this post.
Familiar, Python-native, local-first developer experience
ML engineering is highly iterative, which means an excellent developer experience is non-negotiable. Rift is Python-native and runs in familiar environments (terminal, notebooks, IDEs, cloud platforms) and uses familiar languages (Python and SQL). The system enables seamless transitions between local development and production deployment without code rewrites.

Scalable, efficient and portable across all workloads
Rift handles both experimental and production workloads efficiently, scaling automatically from small local datasets to large remote datasets. The system optimizes resource usage and performance across the entire data pipeline. Rift connects natively to diverse data sources and integrates into existing data infrastructure. Instead of forcing users to adapt their workflows this enables incremental adoption with minimal configuration overhead.

Faster time to market with lower operational cost
Rift’s core engine is built and controlled in-house rather than relying on third-party vendors, enabling rapid adaptation to new platforms and technologies. This architectural approach has already demonstrated success by accelerating implementation of Google Cloud support (using GCE instead of EC2) and BigQuery SQL (through an Arrow-native connector). By maintaining control of the core technology, Rift provides a consistent user experience while easily supporting fragmented data stacks and rapidly delivering new capabilities to market.
Design Tradeoffs
The principles above forced us to make intentional tradeoffs when designing Rift:
- Building an architecturally simple, lightweight, flexible engine would gracefully handle the majority of workloads (estimated 95th percentile), but the long tail of very-large (100TB+) workloads are better suited to run on Spark or other distributed compute engines. We plan to continue investing in Tecton’s deep Spark integrations for this reason. In addition we are constantly improving the performance of Rift to handle larger workloads.
- An architecture optimized for local development means Rift’s offline query performance is constrained by your workstation or cloud environment’s (e.g. Google Colab) hardware. We’ve mitigated this tradeoff by making it extremely easy to spin up a compute job in the cloud and run these workloads remotely (more on “Remote Dataset Generation” below). Our goal is to continue investing in this to ultimately blur the line between local compute and remote (cloud) compute.
Building Blocks of Rift
TL;DR: Rift ♥️ Apache Arrow + DuckDB + Ray
DuckDB, the sharpest tool in the shed
We bet on DuckDB when building Rift, and the decision has paid dividends over time. DuckDB is a fast, in-process analytic SQL engine with performance and an ecosystem that continues to improve over time (ASOF joins keep getting better!) It’s a single binary with zero external dependencies built ground-up, prioritizing performance, portability, and interoperability as paramount requirements.
DuckDB’s columnar architecture delivers exceptional performance for analytical workloads while maintaining a small footprint, making it ideal for both local development and production environments. Its versatility across computing environments is crucial – whether running on a developer’s laptop or scaling vertically on high-memory EC2 instances, DuckDB maintains consistent behavior and impressive performance. This enables Rift to handle both small experimental datasets and production-scale feature engineering tasks without code rewrites.
Finally, it also allows us to create our own extensions so support new aggregations and transformations for complex features that aren’t available by default in DuckDB.
Apache Arrow, the universal data format
Behind the scenes, Apache Arrow is a key player in today’s data ecosystem that enables Rift. Nearly every major data tool is built on or tightly integrated with Arrow.
Arrow is a specification for an in-memory, columnar format for tabular data. Columnar formats have long been the standard for high-performance analytic query engines, but each engine previously had a proprietary columnar format, each subtly different from the next. This fragmentation meant data passed between engines incurred memory and execution time penalties to re-encode data. Arrow’s innovation is a standard format that multiple engines have adopted to enable interoperability without paying conversion costs. Arrow is an important interoperability layer that allows mixing and matching tools like in-process query engines (e.g. DuckDB), data frame libraries (e.g. Pandas), and remote data sources (e.g. Snowflake).
Ray, the orchestration backbone
Ray plays a crucial role in Rift’s architecture, providing robust orchestration capabilities even within our single-node system. It enables seamless cross-language execution between our Python query engine and Kotlin-based database writers, while offering built-in monitoring and observability tools that accelerate development and debugging.
A key advantage of Ray is its containerized execution environment, allowing Rift to run queries with various Python dependencies while maintaining stability. Additionally, Ray’s ability to partition datasets and launch parallel tasks within a single EC2 instance has significantly improved performance for point-in-time training data generation, optimizing resource utilization without requiring a multi-node setup. By integrating Ray, Rift gains the flexibility and reliability needed to scale analytical workloads efficiently, while keeping the system lean and production-ready. Our eventual goal with Ray is to distribute large jobs across multiple nodes instead of just a single node.
Rift Architecture
Example feature pipeline
Let’s explore a common feature engineering use case: computing trailing window aggregations for e-commerce click data. In this example, we’ll calculate the 1-hour and 2-hour count of clicks per item (clicks_1h and clicks_2h).
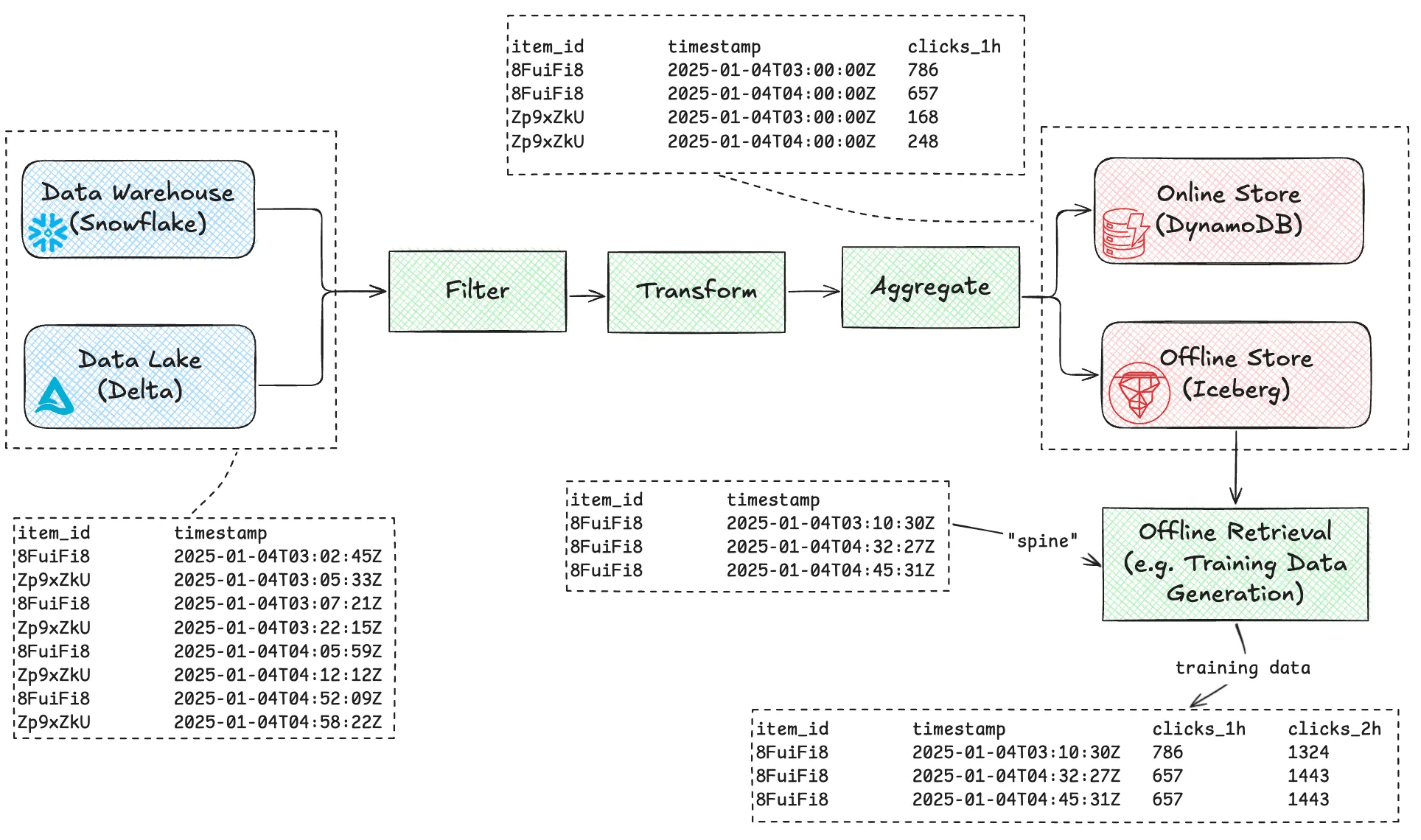
Feature Pipeline Flow
A typical feature pipeline consists of four key stages:
- Extract: Reading event data from sources like Snowflake or a data lake.
- Transform: Applying filters, transformations, and aggregations to compute features.
- Load: Writing processed feature data to online and/or offline storage for efficient retrieval.
- Retrieval: For training datasets, joining feature values with input rows (“spine”) aligned to provided timestamps.
📌 Note: In this example, a 1-hour and 2-hour sum of clicks features are computed. This pattern of using the same aggregation over multiple time windows is common in feature engineering use cases, so we have built support for serving both of these features based on the same underlying data in the Feature Store by doing a final rollup aggregation at serving time.
Query execution in Spark vs. Rift
These 4 query execution steps were previously implemented as two Spark queries. 1-3 compose the “materialization query”, which runs periodically as new data arrives, and 4 is the “retrieval query”, which is run by users on-demand to generate training datasets or batch predictions.
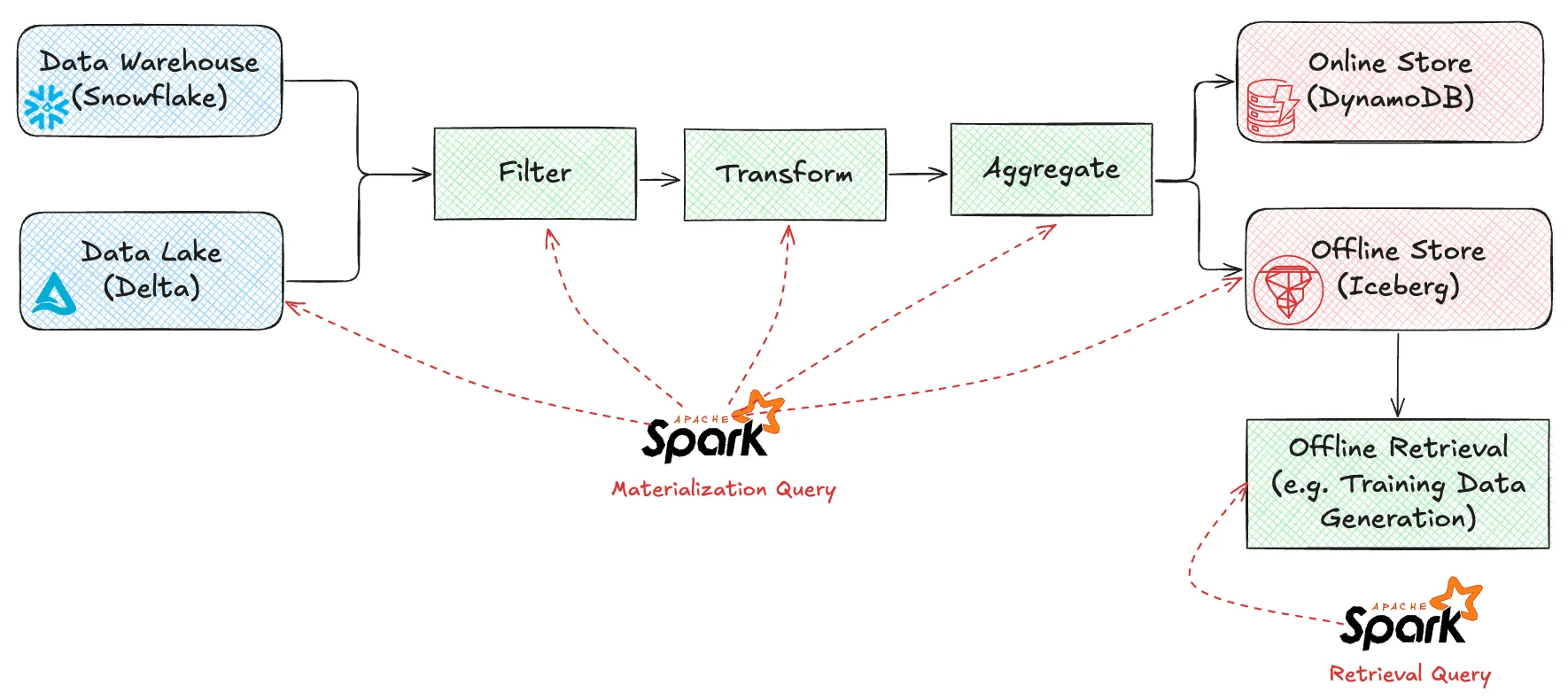
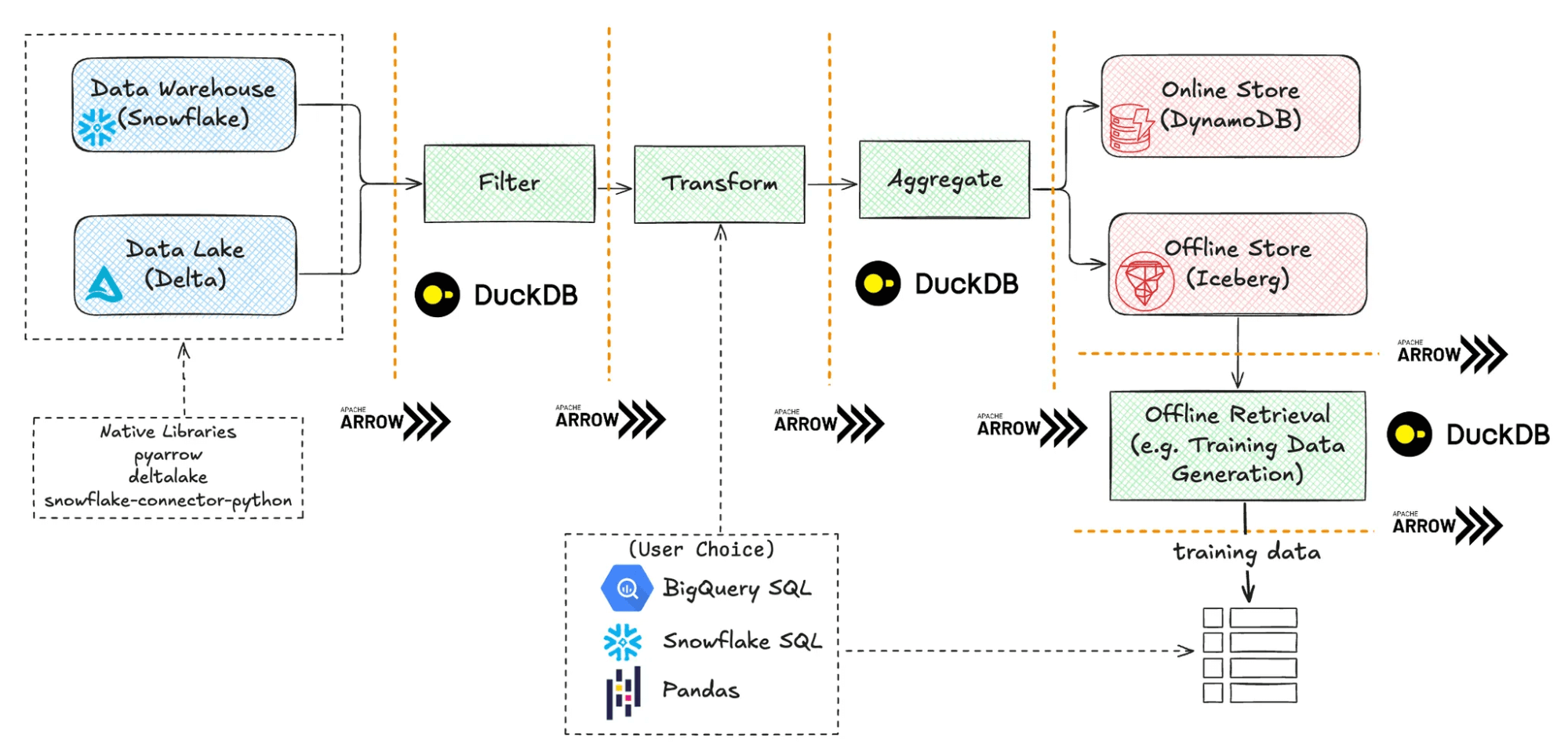
In Rift, pipeline stages are implemented using smaller, more focused components. This strategy provides flexibility in choosing the best technology for each stage instead of relying on an all-or-nothing technology (this follows an increasingly common pattern in databases). In the diagram below, note that the Arrow data format is used as a conduit between components, and DuckDB is used for transformation in each component.
Debugging and Observability
Smaller, focused stages also provide finer-grained control over the logical and physical query execution plan. For example, any TectonDataFrame allows users to explain its query execution tree for debugging, and even step through a subtree if needed. For example:
# Compute features from May 1, 2024 to January 31, 2024
df = user_transaction_amounts.get_features_in_range(
start_time=datetime(2024, 5, 1),
end_time=datetime(2024, 12, 31)
)
df.subtree(node_id=8).explain(descriptions=False)Output
# Render a query subtree responsible for ASOF join logic.
<1> AsofJoinFullAggNode(spine, partial_aggregates)
├── <2> [spine] ExplodeTimestampByTimeWindowsNode
│ └── <3> RenameColsNode
│ └── <4> PartialAggNode
│ └── <5> StagingNode
│ └── <6> FeatureTimeFilterNode
│ └── <7> ConvertTimestampToUTCNode
│ └── <8> FeatureViewPipelineNode(transactions_batch)
│ └── <9> [transactions_batch] StagingNode
│ └── <10> DataSourceScanNode
└── <11> [partial_aggregates] PartialAggNode
└── <12> StagingNode
└── <13> FeatureTimeFilterNode
└── <14> ConvertTimestampToUTCNode
└── <15> FeatureViewPipelineNode(transactions_batch)
└── <16> [transactions_batch] StagingNode
└── <17> DataSourceScanNodeReading from data sources
By using Arrow and DuckDB, Rift has efficient connectors to read from most data sources supported by Tecton.
- Pyarrow, the Python language Arrow library, natively supports loading from popular open source file formats such as Parquet.
- DuckDB also natively supports file formats like Parquet and “advanced” data lake formats like Delta and Iceberg.
- Proprietary data sources such as BigQuery and Snowflake provide first-party Arrow connectors to support loading data.
Python-native means any standard function returning a Pandas or PyArrow dataframe also works:
from tecton import pandas_batch_config
@pandas_batch_config()
def parquet_data_source_function():
import pyarrow.parquet as pq
from pyarrow.fs import S3FileSystem
dataset = pq.ParquetDataset(
f"s3://tecton.ai.example/path/to/data/",
filesystem=S3FileSystem(),
)
return dataset.read_pandas().to_pandas()For a real-world example, you can also see in this example how we can build a batch connector to Postgres very easily using either Pandas / PyArrow.
Transformations
One of Rift’s import requirements was allowing users to write transformations using familiar tools. With Arrow, Rift efficiently supports any DataFrame library or query engine with Arrow support. For now, it supports Pandas and DWH SQL, but we may consider other query tools in the future like Ibis. In the diagram above, the Transform stage can be expressed using either DWH SQL or Pandas.
Writing to offline and online storage
Rift leverages Arrow’s efficient format to write directly to offline storage systems like Parquet, Delta, and Iceberg. This enables high-performance data persistence for historical feature values and batch training datasets. For online stores such as DynamoDB and Redis that don’t natively support Arrow formats, Rift utilizes JVM-based writers shared with Spark implementations. This dual approach ensures optimal performance across different storage paradigms while maintaining compatibility with existing infrastructure.
Job Orchestration with Ray
Rift jobs are orchestrated using Ray, which is provisioned through Tecton’s job orchestration service. Ray serves as an ideal framework for managing the complete lifecycle of Python jobs in the Rift ecosystem. Users gain flexibility through custom dependency configuration via Tecton Environments, allowing teams to tailor their execution environment to specific requirements. The combination of Ray clusters with single-node compute architecture significantly simplifies job management compared to the complexity of managing distributed workloads across Spark clusters.
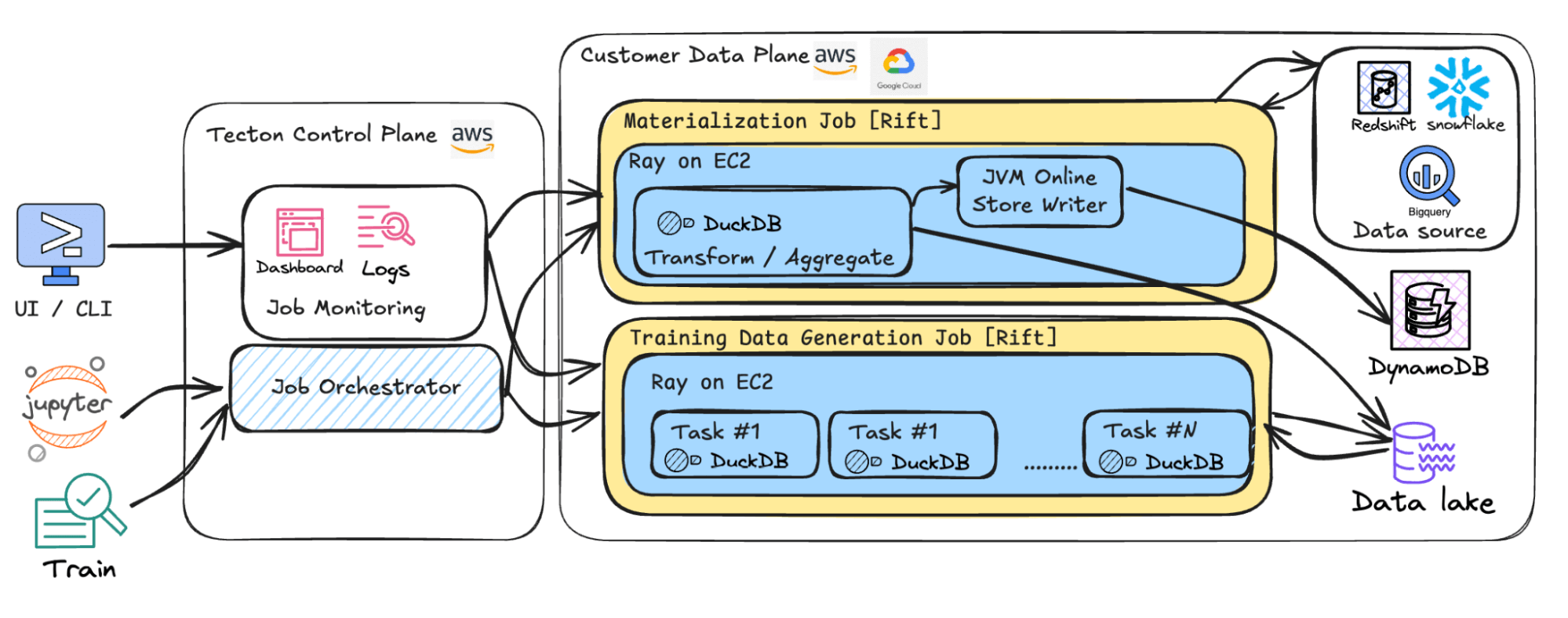
System Architecture Diagram
Putting all of the above together, here is a 10,000 foot overview of Rift’s system architecture.
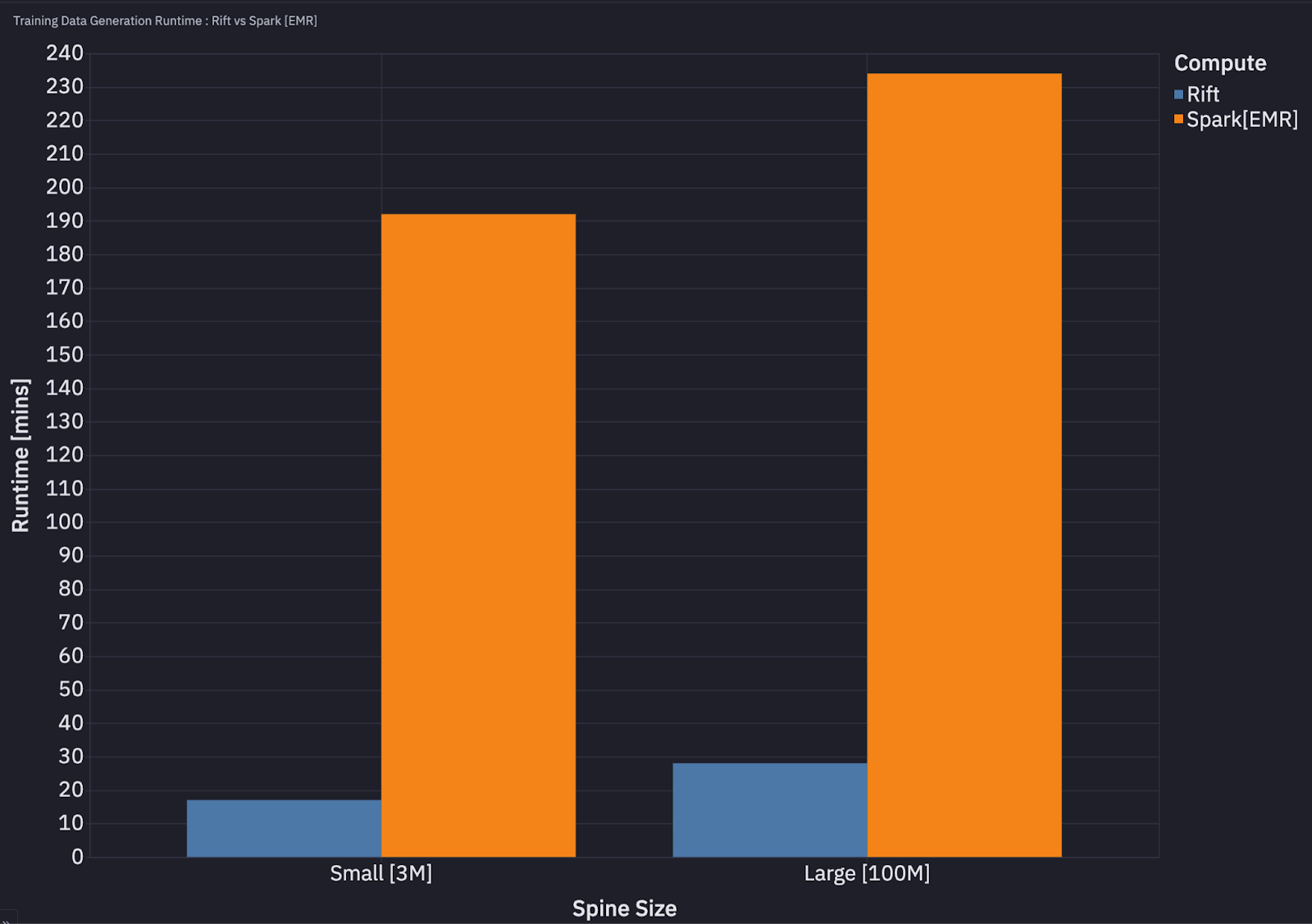
Benchmark: Rift vs. Spark on AWS EMR
Training Data Generation Performance
We conducted comprehensive benchmarks comparing Rift against Spark on Amazon EMR for one of the most computationally intensive workflows in ML feature engineering: point-in-time training data generation.
This process involves joining a user-defined spine (entities with time ranges) with historical feature data from Tecton’s offline storage, ensuring temporal correctness of all features across entities and specified time windows. Time-travel joins are notoriously expensive in distributed systems due to their data movement requirements.
Test Configuration
- Data Characteristics:
- Offline store data volume: 900MB per day (stored in daily partitions)
- Historical data range: 30 days
- Total data processed: ~27GB
- Test Scenarios:
- Small Scale Training Data Generation: 3 million entity-timestamp pairs in spine for point-in-time join
- Medium Scale Training Data Generation: 100 million entity-timestamp pairs in spine for point-in-time join
- Cluster Infrastructure
- Rift: 1 Node, Instance Type: r5.24xlarge
- Spark [EMR]: 12 Nodes, Instance Type: r5.2x large. Using larger sized instances (for example, 2 r5.12x large nodes) resulted in worse performance.
Runtime Comparison
Cost Comparison
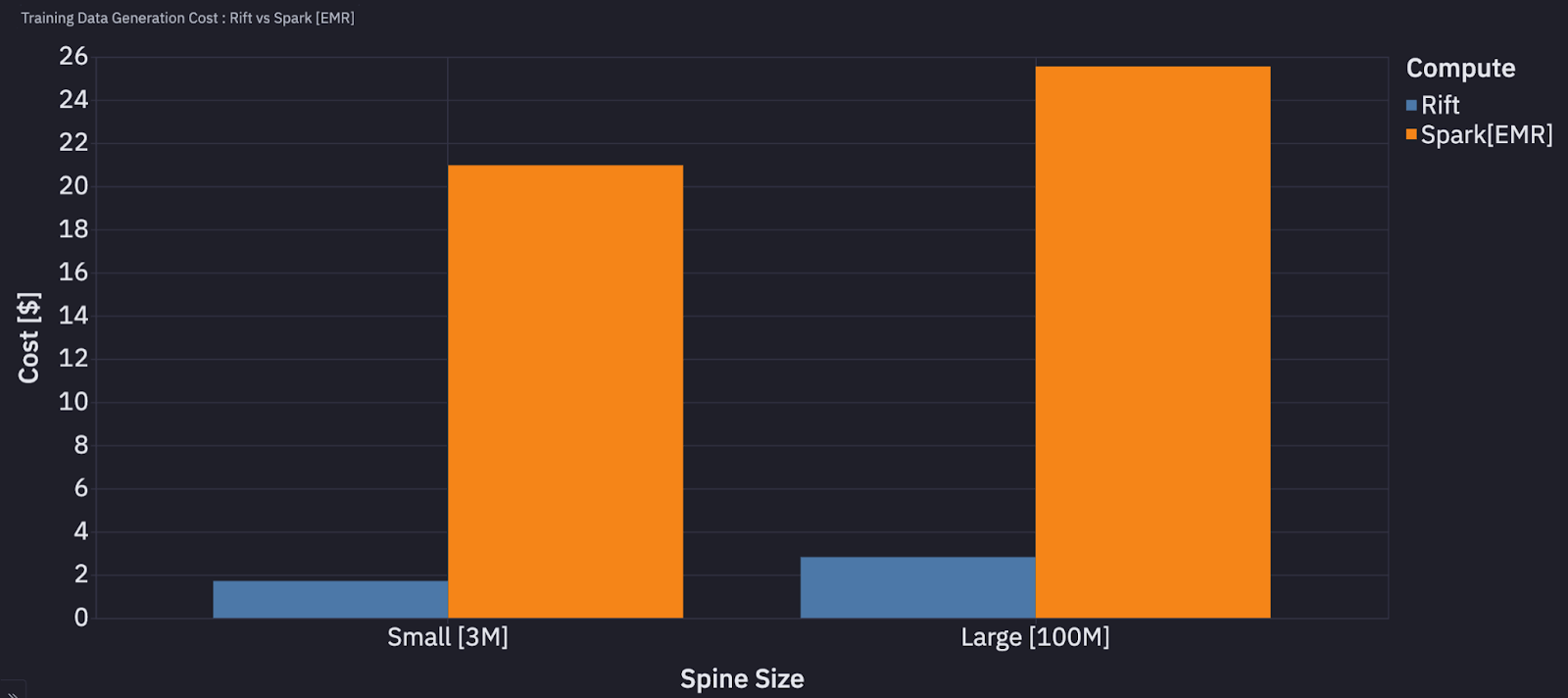
Across both these scenarios Rift was ~10x cheaper and faster than Spark. These benchmarks demonstrate that for these representative ML feature engineering workloads, our single-node Rift architecture significantly outperforms traditional distributed Spark clusters while consuming fewer resources and reducing operational costs.
Rift as a building block
The portability and flexibility of Rift has made it an internal building block across Tecton data flows. The focus of this post is feature pipelines that read records from data sources and transform them into feature values that are written to managed storage, but Rift can be used in several other contexts:
- Develop features locally (for example, our quickstart can be run locally with nothing but a Tecton API token or user account) – iterate on Tecton repositories and interact directly with your data in any environment: your laptop, Google Colab notebook, a Modal job – anything that supports Python works.
- Remote dataset generation – generate large datasets as a job, rather than locally in your Python environment.
- Publishing Features to external storage – write copies of features to external storage layers after they’re computed and written to the Tecton-managed offline store.
- Tecton-managed Embeddings — manage high-dimensional data in addition to tabular data in Tecton.
Code Examples
Check out our sample GitHub repository for more examples of feature pipelines defined using Rift.
What’s next?
Rift has continued to gain momentum among Tecton’s customer base since its initial Private Preview release in early 2024. In 2025, we plan on graduating Rift to General Availability with several improvements spanning deployment and configuration, debugging, observability, UX, and overall performance. In addition, Rift continues to provide the building block for new dataflows through Tecton.
If you’re interested in working on Rift, we’re hiring!
📌 Acknowledgements: Rift would not have been possible without the invaluable contributions, dedication, and expertise of several individuals. We extend our sincere gratitude to Oleksii Moskalenko, Alex Sudbinin, Vitaly Sergeyev, Liangqi Gong, Zheming Zheng, Cong Xu, Krishnan Rangachari, Mike Eastham, and Matt Bleifer. Their vision, technical depth, and hard work were instrumental in bringing Rift to reality.