Introducing AI-Assisted Feature Engineering with Cursor & MCP



How I built an AI that’s better at writing ML model features than I am
Since leaving Uber’s ML team almost 7 years ago, I have worked with hundreds of teams who implement and scale machine learning initiatives throughout their organizations. From Fortune 100 corporations to rapidly growing FinTech startups, each organization presents unique requirements. Nevertheless, I’ve seen nearly all of them struggle with:
- Hiring and retaining deeply technical ML Engineers who can build production ML applications
- Escalation of commitment to an existing tech stack that’s just barely good enough to overhaul, yet in reality, too expensive to keep
- Fear of high migration costs and year-long timelines that prevent taking the first step to a better system
I believe that AI-assisted ML Engineering is about to change this.
For software engineers, AI-assisted coding with tools like Cursor and GitHub Copilot has already unlocked large productivity gains in many companies. Now, it’s ML Engineering’s turn. ML Engineers build feature pipelines, training pipelines, and model inference systems. At Tecton, we’ve spent years making it faster and easier to develop real-time inference systems for use cases like fraud detection, account takeover prevention, underwriting, and recommendations.
But while the barrier to production ML has lowered, it’s still a significant undertaking and out of reach for many teams. However, with the advent of AI-assisted coding, we’re seeing an accelerator that will make sophisticated real-time ML applications accessible to a much wider audience.
Imagine Alice: a new ML Engineer who was hired by neobank Wealth Fargone, who is struggling with massive fraud losses. As a fluent SQL-native, she has a working feature that’s expressed in Snowflake SQL. She now wants to productionize this feature and make it available for low-latency serving & point-in-time correct training data generation. Normally, Alice would need to dig through internal wikis, guess how the existing data pipeline infrastructure works, or wait for another engineer to help them out.
With AI-Assisted Feature Engineering, this is becoming much easier. By leveraging Cursor, MCP, and Tecton, she can speak to an agent in plain English, and the system will do the rest: write the feature code, write a unit test, validate the syntax & semantics, and even fix any validation errors autonomously. Check out this quick demo:
(For more examples, see section at the end of this blog)
In this blog post, I will share how Tecton’s Cursor integration works and the lessons we’ve learned along the way.
Inside the Cursor, Tecton & MCP Integration
At a high level, we’re leveraging both MCP and Rules to enable AI-assisted Feature Engineering directly within the coding IDE:
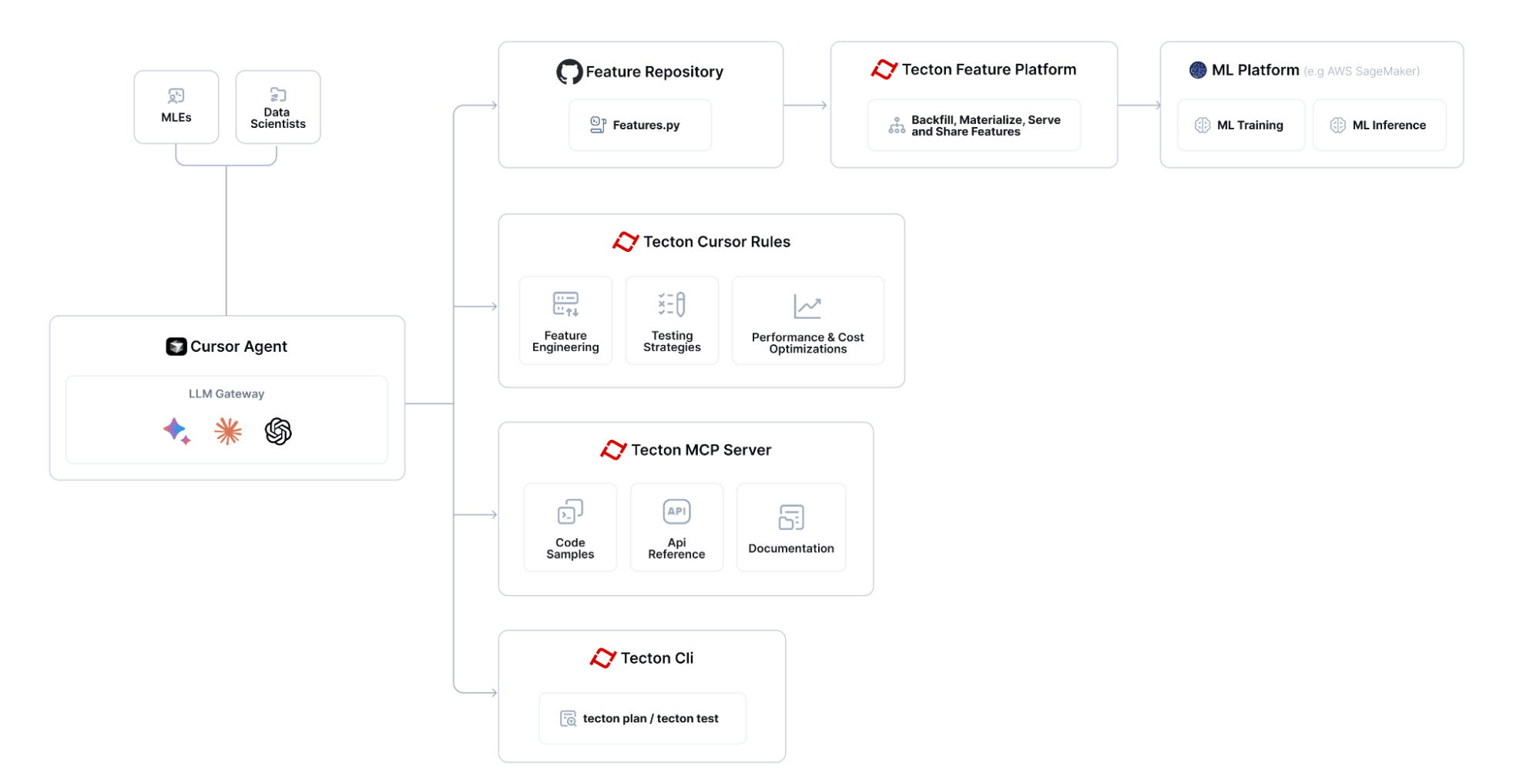
Key building blocks:
MCP Server:
- Tecton’s MCP server enables MCP Clients like Cursor, Windsurf, or Block’s Goose to browse a code snippet library of Tecton feature pipelines, query the Tecton docs, and interrogate Tecton’s SDK API reference.
- By default, the MCP server is running locally in the MLE’s coding environment (such as a laptop) and is implemented using the official Model Context Protocol Python SDK. It can easily be ported to a backend server.
Tecton Cursor Rules:
- Rules are the “System Prompt” we’ve configured to teach the Cursor Agent (or really, its underlying LLM) how to best approach solving common problems like building a new feature or creating a unit test.
Tecton CLI:
- Cursor can validate a feature repository using Tecton’s CLI by running the command “tecton plan”. This allows the Cursor agent to run in a control loop and autonomously fix any syntactical issues.
This is what’s going on behind the scenes:
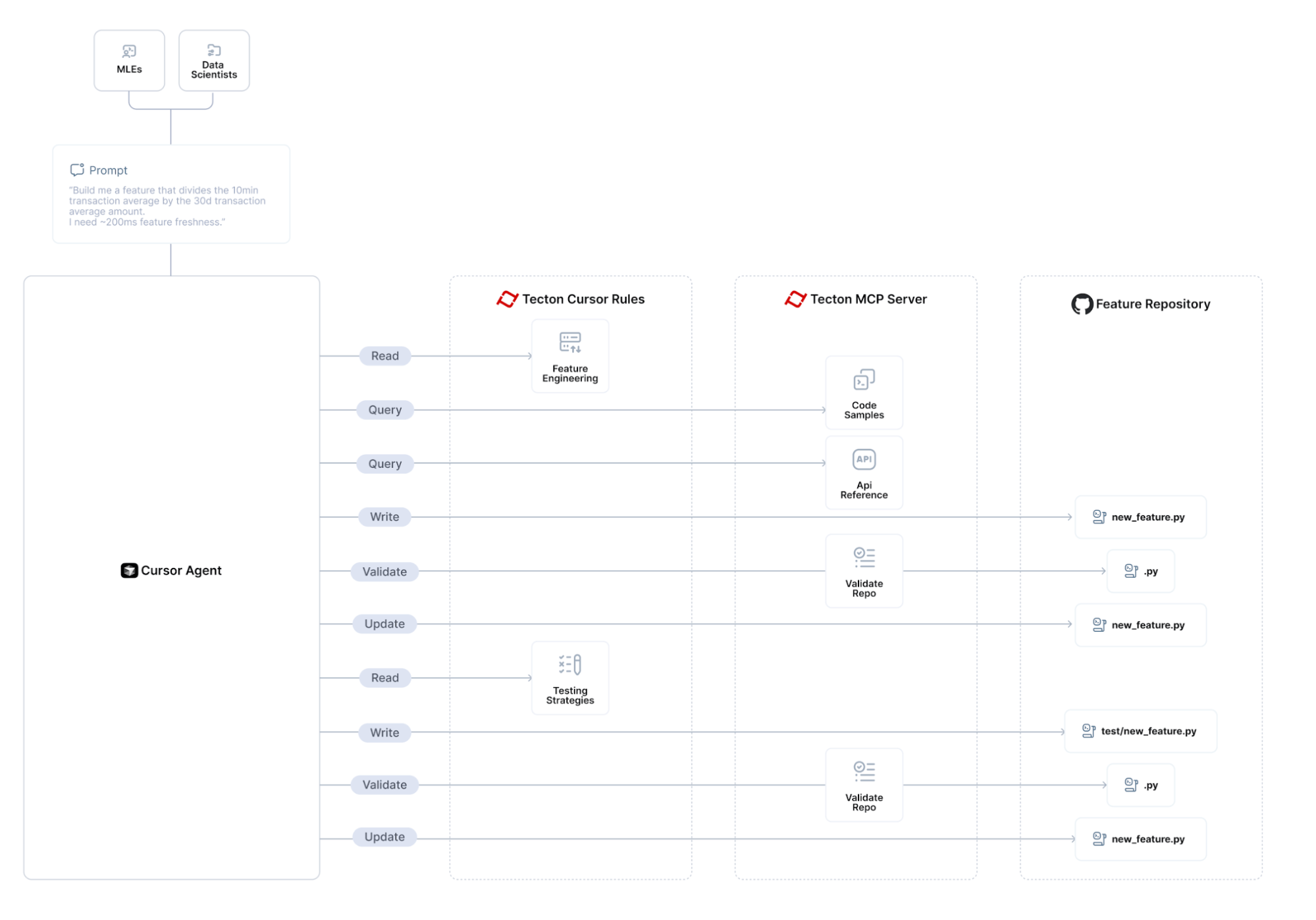
The Cursor agent executes in a control loop, combining rules and tools to accomplish its assigned task.
What makes this powerful is the level of transparency and flexibility: users can see exactly what the agent is doing – what tools it invokes, which rules it’s referencing – and can step in to override or guide the flow at any point. Users can further fully customize this control flow with their own MCP tools and rules. That’s critical because AI-assisted coding today still requires human supervision. It’s not autonomous coding; it’s collaborative coding, with the user in the driver’s seat.
Lessons Learned building the agent
Building Tecton’s Cursor integration has been an extremely fun and at times surprising experience. Below are some of my main takeaways and expectations for the future.
Public Docs allow LLMs to hit the ground running

I’m so glad we made our Documentation public years ago. As a result, pretty much every foundation model out there knows of Tecton and is able to hit the ground running.
SDK Interface instability confuses agents

While it’s great that foundation models already know of Tecton’s API, there is a hidden cost: Given that the cut-off time of LLM’s training data is at some point in the past, I observe all the time that LLMs are reverting back to writing feature code that’s great with an old version of Tecton, but not the latest one. They are essentially biased towards and primed to use an old version of Tecton. As a result, the first shot attempt at writing a Tecton pipeline fails, and the agent needs to work its way through validation errors until it eventually arrives at a version that’s compliant with the latest version.
Tecton’s MCP server made the biggest difference to this problem as it allows the LLM to “see” code examples with the latest SDK. But, ideally, you keep your APIs stable and make as few backward-incompatible changes as possible.
Designing for Agents: How Developer Experience is Evolving
When an agent gets something wrong, I can’t always blame an old version of Tecton. Very often, it highlights a Developer Experience issue that would trouble a human, too. The error message might be vague, the documentation could be missing a clear example, the docstring could be stale and provide outdated examples, or the function signature isn’t self-explanatory. In fact, an agent’s confusion has become a surprisingly effective litmus test for unintuitive parts of the product — they’re like your most honest users who don’t get tired and don’t pretend to understand.
That said, I’ve also found that agents have preferences that differ in some ways from humans. They don’t care about visual polish or progressive disclosure of complexity. They value completeness, unambiguous structure, and machine-readable scaffolding. They take docstrings much more seriously than your average software engineer does. They get thrown off by incorrect examples more easily than a human, but can skim 50 examples in seconds.
We need Test-Driven Development more than ever

AI-assisted coding is inherently non-deterministic. There’s no compiler or interpreter that can guarantee correctness. Given that humans aren’t writing every line of code anymore, and they will realistically not carefully review every AI-written line of code either, we need rigorous testing more than ever.
Besides helping ensure correctness, a powerful suite of unit and integration tests that can be invoked by an agent has another big advantage: AIs operate in a control loop to achieve a goal. When validation fails, they don’t stop and just give up. They iterate, refine, and try again until the validation passes. That effectively turns your test suite into the agent’s north star. In this world, the quality of the AI-generated outcome is only as good as the quality of your test suite.
Rapid foundation model progress is eating boilerplate prompt hacks

In the early days, GPT-4o showed the most promise for us. But it wasn’t long before Sonnet 3.5 overtook it. Then Sonnet 3.7 in “thinking mode” became my new favorite. Most recently, Gemini 2.5 has taken the lead, at least in my own hands-on testing. (Update from April 17: OpenAI’s o3 seems to be the front-runner now)
The pace of progress has been impressive. But what’s been most exciting is what each new model allows us to remove. With every upgrade, we’ve thrown away more brittle prompt-engineering code, more custom scaffolding, and more boilerplate rules.
I now believe it won’t be long before our Tecton Cursor Rules can be drastically simplified or even eliminated. In fact, I treat the amount of Cursor Rule complexity I need to write as a kind of proxy: a reflection of both the limitations of the foundation models and the developer experience of our own system. As both continue to improve, the complexity of those rules should asymptotically approach zero 🤞
Agents perform amazingly well with declarative, “as-code” platforms

LLMs shine in environments that support structured, machine-readable, “as-code” configuration. They’re great at writing code, iterating quickly, and autonomously fixing issues surfaced by compilers or interpreters. This makes platforms with declarative, code-based configurations ideal candidates for AI co-pilots.
Years ago, we decided to make Tecton’s feature pipelines fully declarative – defined in simple, clean Python code. That design choice is paying off in the agent era. If Tecton had been purely a drag-and-drop UI, AI agents would struggle to get started or work effectively.
I love Cursor + MCP. But what I really want this summer is Evals and more Model control

Our first prototype of Tecton’s AI Co-Pilot lived entirely outside of Cursor in a standalone web UI with its own chat interface. But as Cursor introduced support for Agent Mode, MCP, and Cursor Rules, it became flexible and pluggable enough to serve as the primary user interface for ML Engineers, allowing me to throw literally 95% of our agent codebase away.
The biggest gap I’ve felt while working with the Cursor agent is the lack of a robust evaluation workflow. When I update Cursor Rules or modify the MCP server, I want to quickly run a test suite against past use cases to ensure I haven’t overfit on the most recent scenario. These evaluation tools will be essential to mature AI agent workflows, and I suspect they’re coming soon (Cursor, Windsurf 👀).
I also would really love to have a way to give Cursor a custom fine-tuned model for sub-tasks. Maybe I could fine-tune a model that gets really good at writing Tecton feature code, and have Cursor always use that when it writes Tecton feature code? But resort to other models for all other tasks?
Are you building ML with AI? Let’s swap notes!
I started this blog with a problem: Despite a lot of innovations, building production ML systems is still fairly hard, slow, and out of reach for many teams. AI-assisted ML Engineering is going to change that. Tools like Cursor, MCP, and Tecton will make it possible for production ML to cross the chasm and become economically viable for a lot more companies:
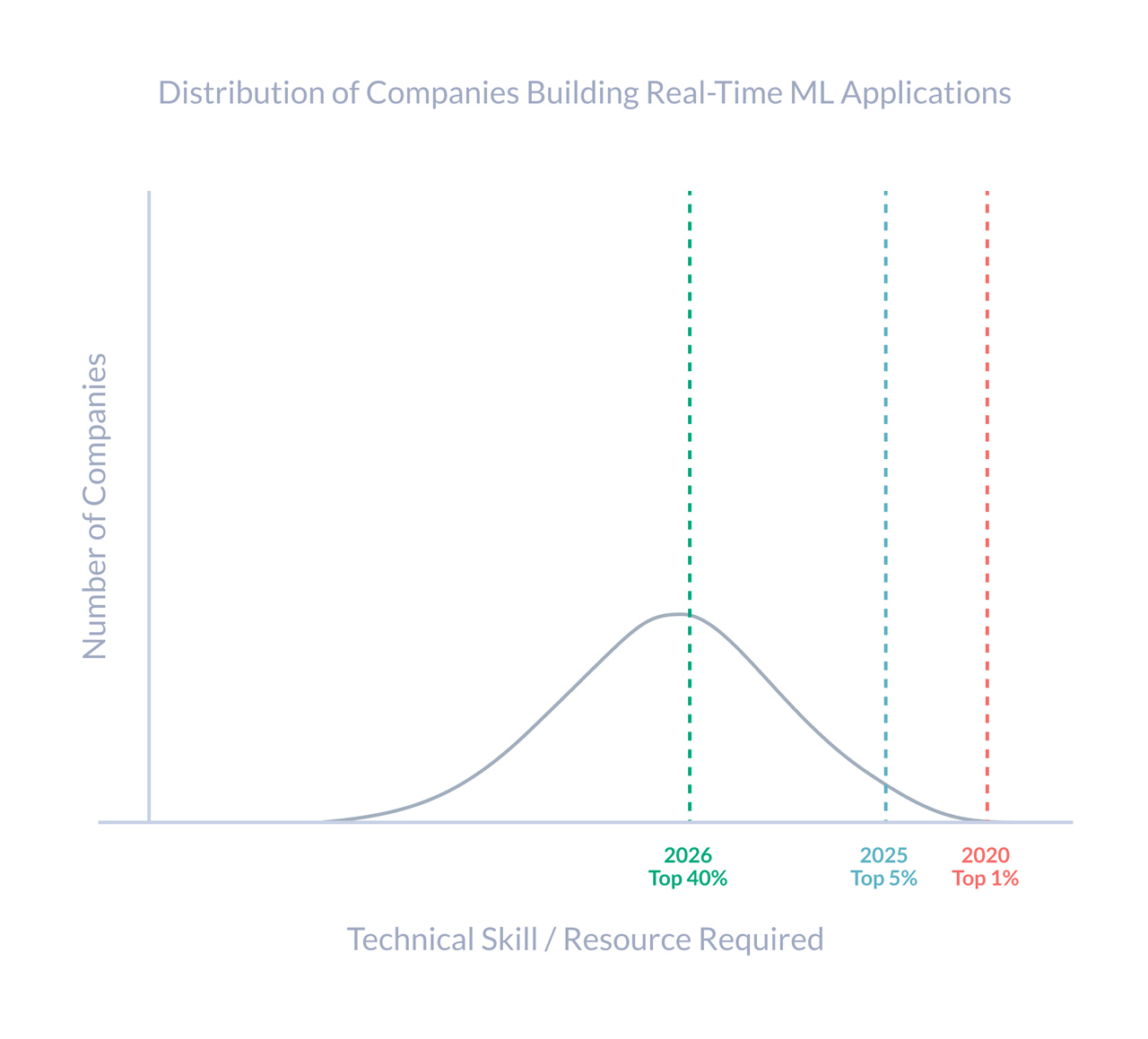
If you’re building in this space, I’d love to compare notes: You can reach me here.