Custom Configuration Options for Spark Clusters


This release unlocks additional flexibility for customers on Databricks & EMR looking to configure Spark clusters used for materialization jobs. This includes the ability to configure a cluster policy ID, custom libraries, notification webhooks, resource allocation, custom tags, and more.
When defining a Batch or Stream Feature View, customers can now pass in a JSON object (DatabricksJsonClusterConfig or EMRJsonClusterConfig) that conforms to the schema used by Databricks / EMR to start new jobs. Tecton’s SDK will modify this object as needed to ensure that materialization jobs work as expected. When enabled, the cluster configuration JSON object is also visible in Tecton’s dashboard:
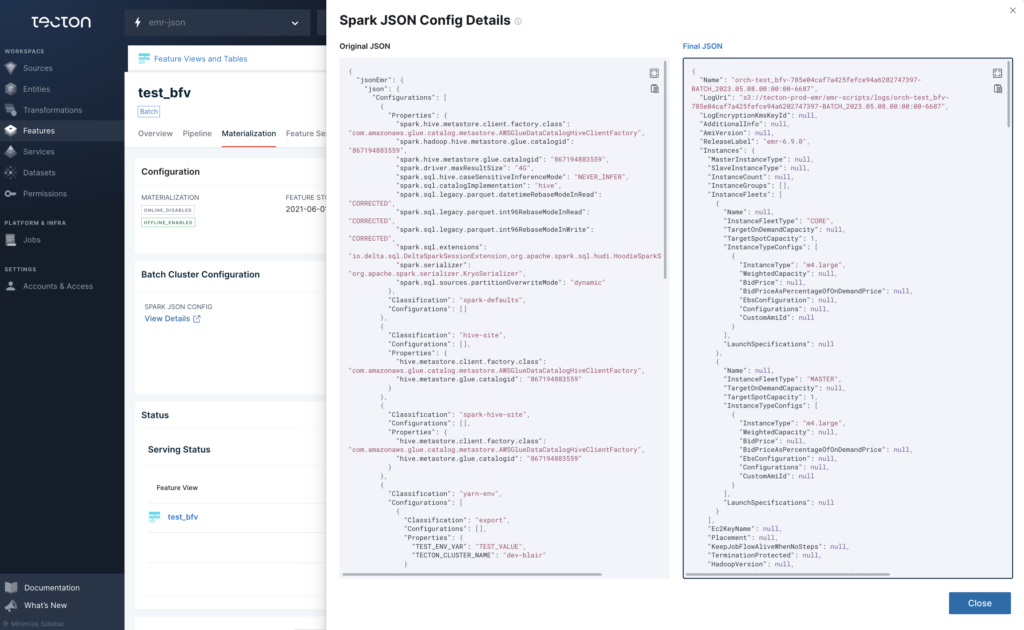
This release also improves visibility into errors thrown by EMR or Databricks during cluster initialization. If a cluster fails to start up due to configuration errors, the error will be visible in the Jobs page as shown below:
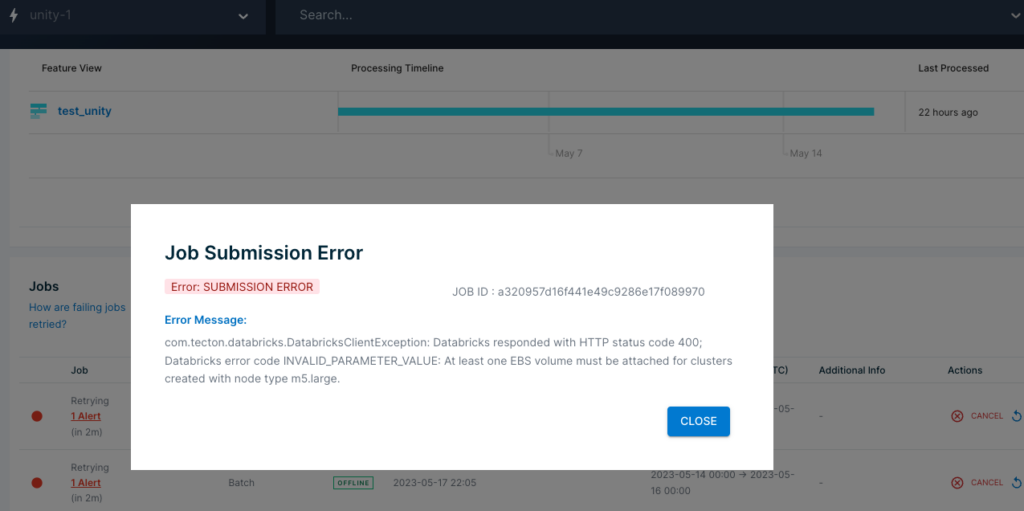
For detailed documentation, including configuration examples and instructions on how to migrate to the new custom configuration options, refer to this page. This release requires Tecton 0.6+.