Announcing Feast 0.10



Learn the differences between Tecton, a fully managed feature platform, and Feast, an open source feature store.
Today, we’re announcing Feast 0.10, an important milestone towards our vision for a lightweight feature store.
Feast is an open source feature store that helps you serve features in production. It prevents feature leakage by building training datasets from your batch data, automates the process of loading and serving features in an online feature store, and ensures your models in production have a consistent view of feature data.
This new release allows you to:
- Run a minimal local feature store from your notebook
- Deploy a production-ready feature store into a cloud environment in 30 seconds
- Operate a feature store without Kubernetes, Spark, or self-managed infrastructure
Let’s dive in!
The challenge with feature stores
In our previous post, A State of Feast, we shared our vision for building a feature store that is accessible to all ML teams. Since then, we’ve been working towards this vision by shipping support for AWS, Azure, and on-prem deployments.
Over the last couple of months, we’ve seen a surge of interest in Feast. ML teams are increasingly being tasked with building production ML systems, and many are looking for an open source tool to help them operationalize their feature data in a structured way. However, many of these teams still can’t afford to run their own feature stores:
“Feature stores are big infrastructure!”
Feature stores require access to compute layers, offline and online databases, and need to directly interface with production systems. This infrastructure-centric approach means that operating your own feature store is a daunting task. Many teams simply don’t have the resources to deploy and manage a feature store. Instead, ML teams are being forced to hack together their own custom scripts or end up delaying their projects as they wait for engineering support.
Towards a simpler feature store
Our vision for Feast is to provide a feature store that a single data scientist can deploy for a single ML project, but can also scale up for use by large platform teams.
We’ve made all infrastructure optional in Feast 0.10. That means no Spark, no Kubernetes, and no APIs, unless you need them. If you’re just starting out we won’t ask you to deploy and manage a platform.
Additionally, we’ve pulled out the core of our software into a single Python framework. This framework allows teams to define features and declaratively provision a feature store based on those definitions, to either local or cloud environments. If you’re just starting out with feature stores, you’ll only need to manage a Git repository and run the Feast CLI or SDK, nothing more.
Feast 0.10 introduces a first-class local mode: not installed through Docker containers, but through pip. It allows users to start a minimal feature store entirely from a notebook, allowing for rapid development against sample data and for testing against the same ML frameworks they’re using in production.
Finally, we’ve also begun adding first-class support for managed services. Feast 0.10 ships with native support for GCP, with more providers on the way. Platform teams running Feast at scale get the best of both worlds: a feature store that is able to scale up to production workloads by leveraging serverless technologies, with the flexibility to deploy the complete system to Kubernetes if needed.
The new experience
Machine learning teams today are increasingly being tasked with building models that serve predictions online. These teams are also sitting on a wealth of feature data in warehouses like BigQuery, Snowflake, and Redshift. It’s natural to use these features for model training, but hard to serve these features online at low latency.

Feast makes it easy to operationalize your feature data for production use. In this example we’re going to show you how you can train a model based on their BigQuery data, then serve those same features in production at low latency using Firestore.
1. Create a feature repository
Installing Feast is now as simple as
pip install feastWe’ll scaffold a feature repository based on a GCP template
feast init driver_features -t gcp A feature repository consists of a feature_store.yaml, and a collection of feature definitions.
driver_features/
└── feature_store.yaml
└── driver_features.pyThe feature_store.yaml file contains infrastructural configuration necessary to set up a feature store. The project field is used to uniquely identify a feature store, the registry is a source of truth for feature definitions, and the provider specifies the environment in which our feature store will run.
feature_store.yaml
project: driver_features
registry: gs://driver-fs/
provider: gcpThe feature repository also contains Python based feature definitions, like driver_features.py. This file contains a single entity and a single feature view. Together they describe a collection of features in BigQuery that can be used for model training or serving.
driver_features.py
driver = Entity(
name="driver_id",
join_key="driver_id",
value_type=ValueType.INT64,
)
driver_hourly_stats_fv = FeatureView(
name="driver_hourly_stats",
entities=["driver_id"],
ttl=timedelta(weeks=1),
features=[
Feature(name="conv_rate", dtype=ValueType.FLOAT),
Feature(name="acc_rate", dtype=ValueType.FLOAT),
Feature(name="avg_daily_trips", dtype=ValueType.INT64),
],
input=BigQuerySource(
table_ref="feast-oss.demo_data.driver_hourly_stats",
event_timestamp_column="datetime",
created_timestamp_column="created",
),
)2. Set up a feature store
Next we run apply to set up our feature store on GCP.
feast applyRunning Feast apply will register our feature definitions with the GCS feature registry and prepare our infrastructure for writing and reading features. Apply can be run idempotently, and is meant to be executed from CI when feature definitions change.
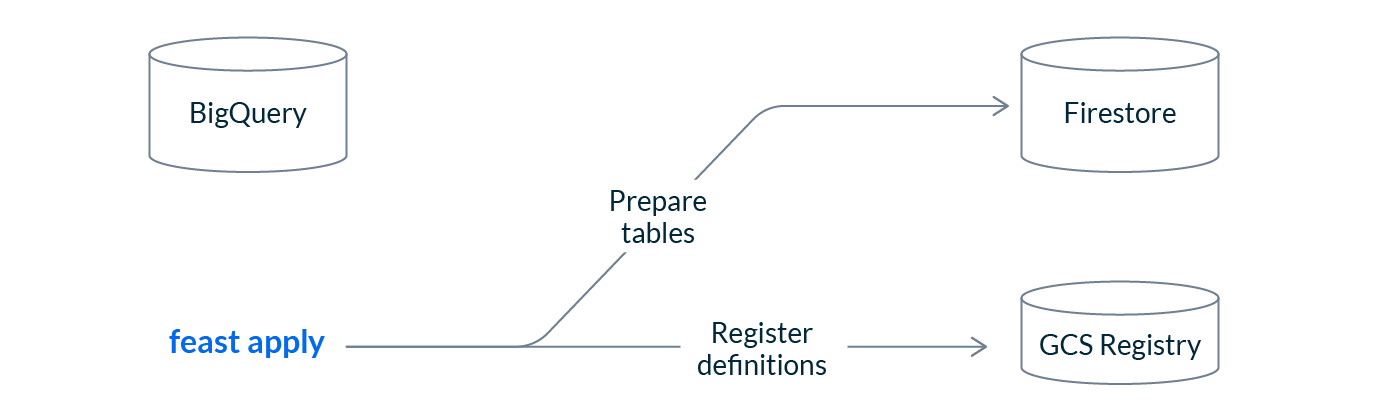
At this point we haven’t moved any data. We’ve only stored our feature definition metadata in the object store registry (GCS) and Feast has configured our infrastructure (Firestore in this case).
3. Build a training dataset
Feast is able to build training datasets from our existing feature data, including data at rest in our upstream tables in BigQuery. Now that we’ve registered our feature definitions with Feast we are able to build a training dataset.
From our training pipeline
# Connect to the feature registry
fs = FeatureStore(
RepoConfig(
registry="gs://driver-fs/",
project="driver_features"
)
)
# Load our driver events table. This dataframe will be enriched with features from BigQuery
driver_events = pd.read_csv("driver_events.csv")
# Build a training dataset from features in BigQuery
training_df = fs.get_historical_features(
feature_refs=[
"driver_hourly_stats:conv_rate",
"driver_hourly_stats:acc_rate"
],
entity_df=driver_events
).to_df()
# Train a model, and ship it into production
model = ml.fit(training_data)The code snippet above will join the user provided dataframe driver_events to our driver_stats BigQuery table in a point-in-time correct way. Feast is able to use the temporal properties (event timestamps) of feature tables to reconstruct a view of features at a specific point in time, from any amount of feature tables or views.
4. Load features into the online store
At this point we have trained our model and we are ready to serve it. However, our online feature store contains no data. In order to load features into the feature store we run materialize-incremental from the command line:
# Load all features from source up to yesterday’s date
feast materialize-incremental 2021-04-14Feast provides materialization commands that load features from an offline store into an online store. The default GCP provider exports features from BigQuery and writes them directly into Firestore using an in-memory process. Teams running at scale may want to leverage cloud-based ingestion by using a different provider configuration.

5. Read features at low latency
Now that our online store has been populated with the latest feature data, it’s possible for our ML model services to read online features for prediction.
From our model serving service
# Connect to the feature store
fs = feast.FeatureStore(
RepoConfig(registry="gs://driver-fs/", project="driver_features")
)
# Query Firestore for online feature values
online_features = fs.get_online_features(
feature_refs=[
"driver_hourly_stats:conv_rate",
"driver_hourly_stats:acc_rate"
],
entity_rows=[{"driver_id": 1001}, {"driver_id": 1002}],
).to_dict()
# Make a prediction
model.predict(online_features)6. That’s it
At this point you can schedule a Feast materialization job and set up our CI pipelines to update our infrastructure as feature definitions change. You’re production system should look something like this:
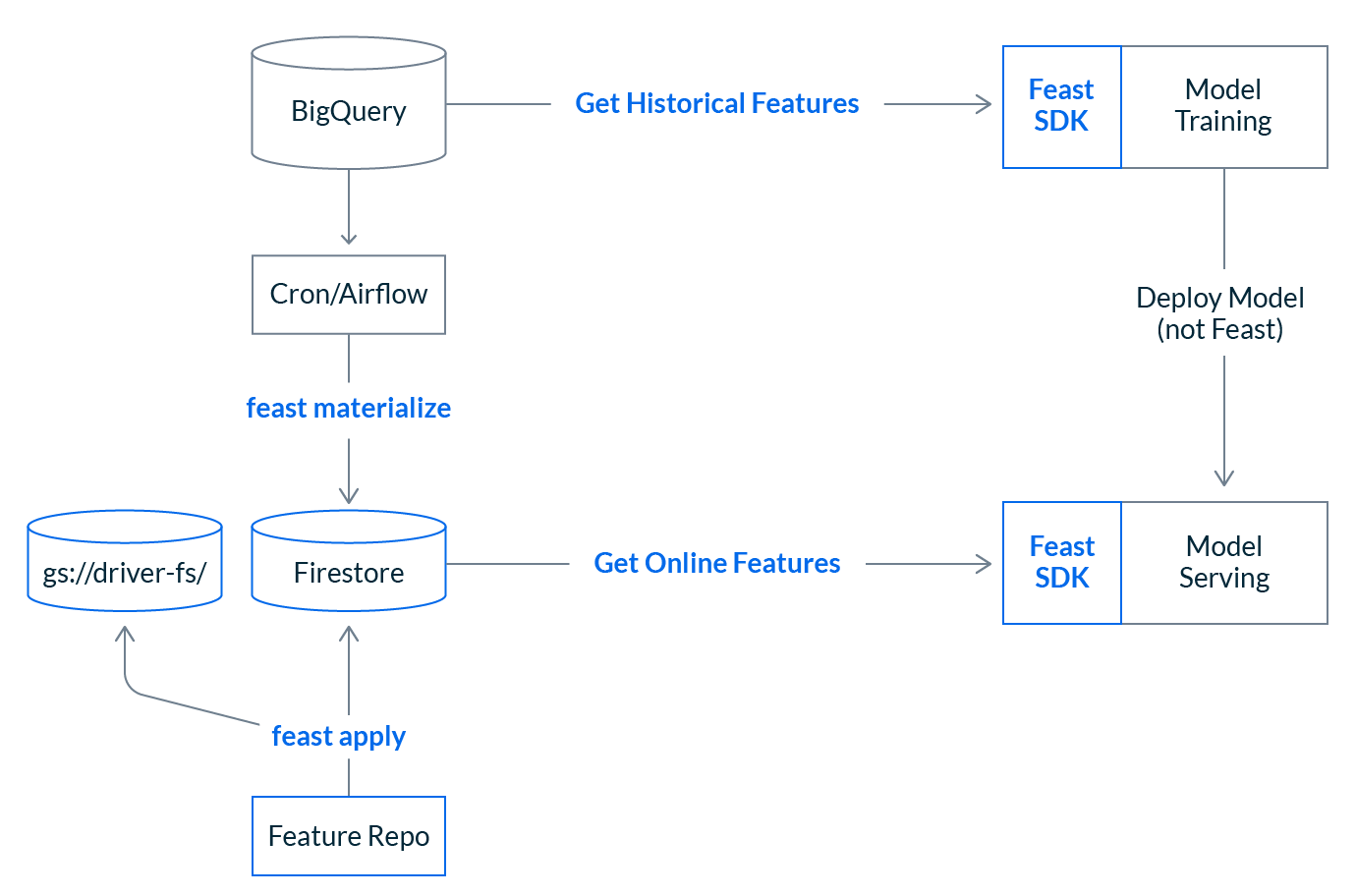
What’s next
Our vision for Feast is to build a simple yet scalable feature store. With 0.10, we’ve shipped local workflows, infrastructure pluggability, and removed all infrastructural overhead. But we’re still just beginning this journey, and there’s still lots of work left to do.
Over the next few months we will focus on making Feast as accessible to teams as possible. This means adding support for more data sources, streams, and cloud providers, but also means working closely with our users in unlocking new operational ML use cases and integrations.
Feast is a community driven project, which means extensibility is always a key focus area for us. We want to make it super simple for you to add new data stores, compute layers, or bring Feast to a new stack. We’ve already seen teams begin development towards community providers for 0.10 during pre-release, and we welcome community contributions in this area.
The next few months are going to be big ones for the Feast project. Stay tuned for more news, and we’d love for you to get started using Feast 0.10 today!
Get started
- ✨ Try out our quickstart if you’re new to Feast, or learn more about Feast through our documentation.
- 👋 Join our Slack and say hello! Slack is the best forum for you to get in touch with Feast maintainers, and we love hearing feedback from teams trying out 0.10 Feast.
- 📢 Register for apply() – the ML data engineering conference, where we’ll demo Feast 0.10 and discuss future developments for AWS.
- 🔥 For teams that want to continue to run Feast on Kubernetes with Spark, have a look at our installation guides and Helm charts.
🛠️ Thinking about contributing to Feast? Check out our code on GitHub!