Expanding Tecton to Activate Data for GenAI




TL;DR: Tecton’s expanded platform now provides unified support for predictive ML and generative AI, enabling organizations to build rich, context-aware AI applications that leverage diverse data types.
At Tecton, we’ve always been laser-focused on one thing: enabling organizations to more easily productionize AI applications. We’ve been at this for 5 years in the realm of predictive ML, and today, we’re making a major leap forward by expanding our platform to support generative AI.
The AI landscape is undergoing a seismic shift. Generative AI has captured the world’s imagination and promises to transform industries. However, there are significant technical hurdles between that potential value and our current reality (similar challenges that historically blocked predictive ML applications). For all their power, most LLMs today are still fundamentally limited in their performance because they lack a true understanding of specific situations and individuals. While smart in a general sense, they fall short in ways that matter most for real-world applications.
For example, when you’re talking to a human expert—let’s say a financial advisor—what makes their advice valuable? It’s not just their general knowledge about finance. It’s their ability to understand your specific situation, your goals, your past financial history, current market conditions, and a host of other relevant factors. They tailor their advice to you.
Now, imagine an AI that could do the same thing. An AI that doesn’t just spout general information, but truly understands the context of each unique situation it encounters. That’s the kind of AI that can deliver real business value.
Smarter LLMs Need Context
Making LLMs “smart” is not just about having a powerful model. It’s about feeding that model the right data at the right time. When we were at Uber building out their AI infrastructure, one thing became clear: the most impactful AI systems are the ones that can understand and address your specific needs by tapping into your proprietary data and using it effectively. Think about the AI-powered products you might interact with every day. The personalization of your Pinterest feed, or product recommendations from Amazon—what sets these systems apart is how they leverage their unique data as context to power these experiences.

While all AI benefits from it, generative AI especially needs context—i.e. all the relevant information it needs to understand a situation or a person. Context can include user information, documents returned from a Vector database in a RAG system, or even conversation history, all fed into the prompt. For predictive machine learning (ML), context is represented as engineered features and embeddings.
The Context Problem for GenAI
There’s a growing need for generative AI models to have access to continuous, comprehensive, and real-time information about customers and the world around them. The challenge lies in providing the level of context these models need. To make things more complicated (and expensive), the engineering overhead gets multiplied because important context is found in both structured and unstructured data. In production environments where trust, performance, and reliability at scale matter, actually surfacing all of the right data to models requires solving some complex challenges:
Assembling Knowledge
The journey from raw data to generative AI-ready context goes far beyond simple data collection. It requires a collaborative effort between data scientists and engineers to extract valuable information from business data and transform it into a format models can efficiently use, and deliver it at the right place at the right time. One major hurdle lies in integrating diverse data types—structured data from databases, semi-structured data from logs and APIs, and unstructured data from documents and images—which come in various velocities: real-time, streaming, and batch. Another challenge is transforming this varied data into a format that models can efficiently use and deliver at the right place and time.
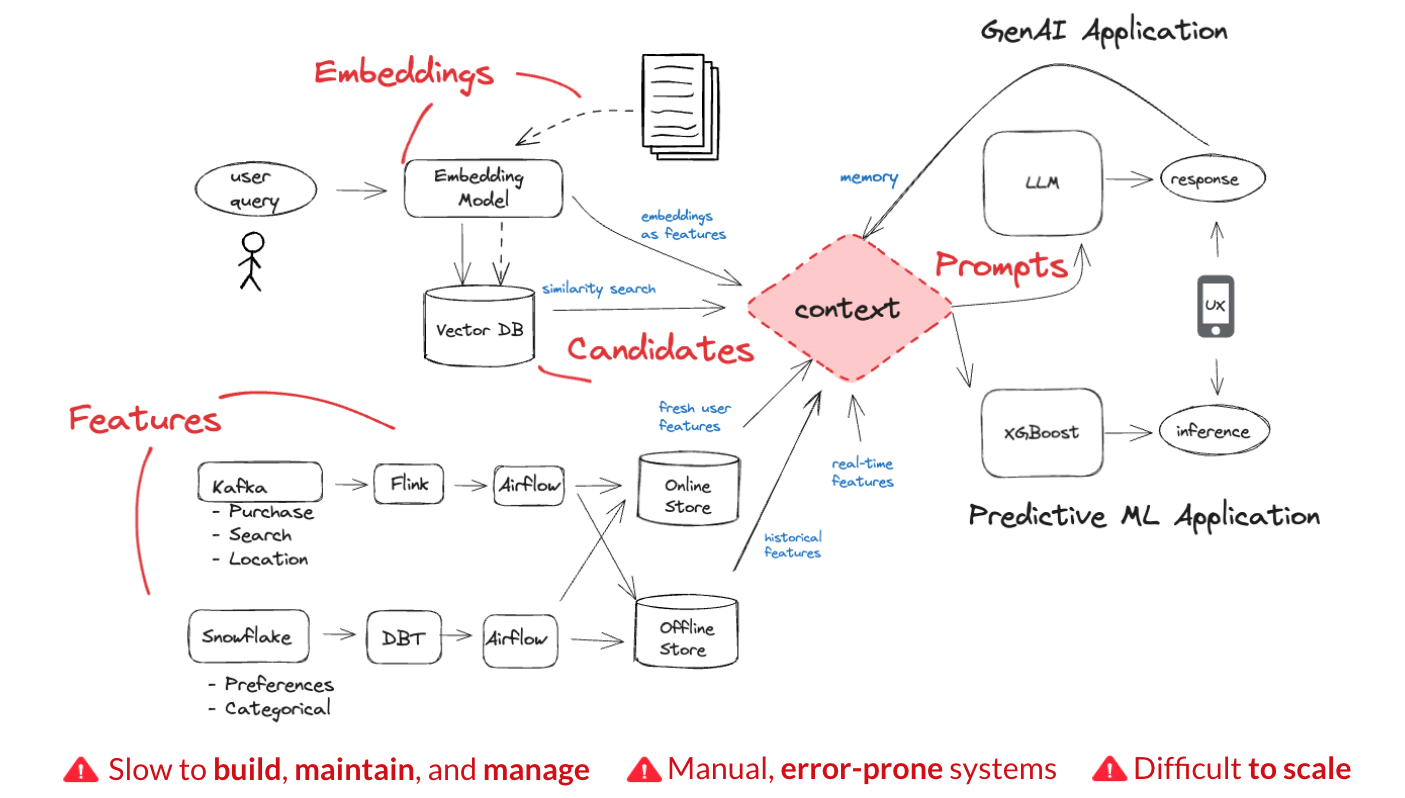
For example, a customer support chatbot might need to combine real-time customer interaction data with historical support tickets and up-to-date customer information. Integrating this data is complex, requiring advanced systems to ingest diverse data types, transform them into AI-ready context, and retrieve them quickly and reliably. The challenge lies in seamlessly handling these processes while maintaining data quality and security, all within a streamlined development environment that allows for rapid iteration and experimentation.
This integrated knowledge base forms a comprehensive repository of your business’s critical information, encompassing all the facts, data, and insights that an AI system might need to make informed, context-aware decisions.
Managing a Knowledge Base
Once created, managing knowledge becomes a monumental task. Version control is critical for ensuring reproducibility and maintaining consistent AI behavior. Governance and compliance require transparent, auditable context for high-stakes decisions. And with AI’s growing influence on critical business operations, it’s more important than ever to control how your data is used for AI.
Additionally, cost management in knowledge assembly and storage is a delicate balance. While more context generally leads to better LLM performance, it also results in more tokens being processed, increasing costs. Organizations need to optimize this trade-off, ensuring they provide enough context for high-quality LLM outputs without breaking the bank.
Retrieving Relevant Knowledge as Context for Inference
When relevant knowledge is retrieved for a specific task, it becomes the “context” for that AI operation.
Context retrieval is the final piece of the puzzle. It’s about providing the right context, at the right time, in the right format, to enable AI models to perform at their peak. People want to use these LLMs to build powerful customer-facing experiences like customer support, personalization, and smart search. Just like any other consumer tech, these experiences need to be fast. For that reason, performance is paramount. Generative AI models, especially those operating in production environments, require ultra-low latency access to context.
Equally as important, you want your recommendations to be based on a current understanding of you/the user. That means the freshness of any context used by the model is super important. In many applications, using outdated context can lead to irrelevant or even harmful outcomes. Again, in customer-facing, production environments, reliability in context retrieval cannot be overstated—these AI systems are powering critical user experiences that directly impact customer satisfaction and business operations, so they need to be consistently available and dependable. Any failure or delay in context retrieval can lead to poor user experiences, lost business opportunities, or even damage to brand reputation.
Our Journey to 1.0
From day one, we’ve been driven by a fundamental belief: every company has the opportunity to build transformational, AI-powered customer experiences, driven by AI that truly understands your business and your customers. With generative AI, that opportunity has never been more apparent.
For most companies, this opportunity isn’t quite within reach yet. Many are still in the experimental phase with LLMs, working on proofs-of-concept. The gap between these experiments and production-ready, business-changing AI applications is significant. That’s the gap we’re bridging with Tecton 1.0.
Our journey to close this gap began long before the current generative AI boom. We’ve been tackling the fundamental data engineering challenges of productionizing AI since we founded Tecton in 2019. We started by creating the ideal feature workflow—one where data scientists can engineer features in a notebook and ship performant features to production with a single line of code, retrieving them instantly when needed.
Our declarative framework has been a game-changer for teams looking to move fast. Define your features once, and we take care of the rest—computing them for training, deploying them to production, and serving them in real time. All the complex data engineering happens under the hood, freeing your team to focus on what really matters: building smart user experiences that drive business value.
Now there’s an opportunity to create even more magical user experiences with generative AI applications. To create them, generative AI needs diverse, relevant, real-time data from across the company. It needs to integrate structured and unstructured data. It needs to serve this data with ultra-low latency. Sound familiar? These are all problems we’ve been solving since our inception.
That’s why with Tecton 1.0, we’re launching a major expansion of our platform to support generative AI.
Our proven platform excels at handling complex data pipelines, real-time serving, and large-scale data management. Customers like Block and Coinbase transform raw data into AI-ready features, providing a solid foundation for AI applications.
Our platform forms the backbone of AI infrastructure for industry-leading companies, serving as a best-in-class foundation for countless mission-critical applications. Trusted for its reliability and performance, it excels in handling complex data pipelines, real-time serving, and large-scale data management. Now, we’re extending our proven expertise in transforming raw data into AI-ready features to the world of generative AI.
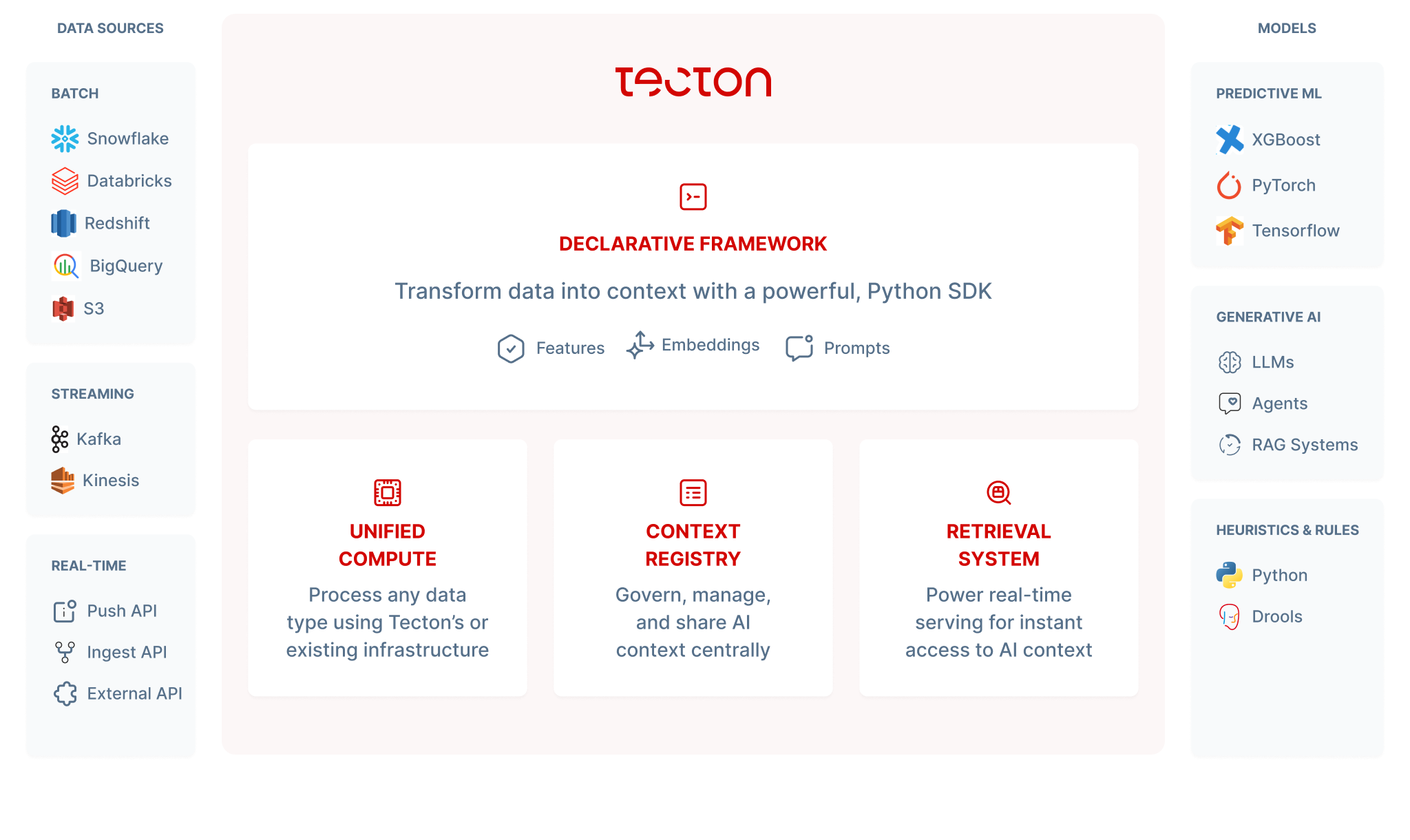
Platform Expansion for Generative AI
What does this mean for you? Tecton now gives you the power to turn your generative AI models into production-ready applications faster and more efficiently than ever. Here’s how Tecton 1.0 is making that happen:
Managed Embeddings: Tecton now offers a managed embeddings solution for generating and managing vector representations of unstructured data, powering generative AI applications. This service handles the entire embeddings lifecycle, reducing engineering overhead and allowing teams to focus on improving model performance. It supports both pre-trained and custom embedding models, enabling faster productionization and cost optimization. The service efficiently transforms text into numerical vectors, facilitating tasks like sentiment analysis and easy comparison across large datasets.
Real-time Data Integration for LLMs: Tecton’s Feature Retrieval API allows LLMs to access real-time data about user behavior, transactions, and operational metrics. This integration enables AI applications to provide more accurate and contextually relevant responses. For example, in customer service, an LLM’s prompt could be dynamically enriched with up-to-date information about a customer’s recent purchases and support history. The API is designed with enterprise security and privacy in mind, ensuring that sensitive data is protected and only authorized models can access specific information.
Dynamic Prompt Management: Tecton’s declarative framework now incorporates prompt management, introducing standardization, version control, and DevOps best practices to LLM prompts. This addresses the challenge of systematic prompt management in LLM application development. The framework enables prompt testing against historical data and provides time-correct context for fine-tuning models. It also supports version control, change tracking, and easy rollback of prompts, driving enterprise-wide standardization of AI practices and reducing compliance risks.
LLM-powered Feature Generation: Tecton’s feature engineering framework now uses LLMs to extract meaningful information from unstructured text data, creating novel features that enhance traditional ML models and LLM applications. This approach bridges qualitative data processing with quantitative analysis, enabling more sophisticated AI applications. For example, an e-commerce company can automatically categorize product descriptions or generate sentiment scores from customer reviews. The framework handles complexities like automatic caching and rate limiting, allowing data teams to focus on defining feature logic rather than managing infrastructure.

Unified Context for Any AI Model
The future of AI isn’t about choosing between predictive ML and generative AI. We envision a future where the dominant AI architecture seamlessly integrates both predictive ML and generative AI to create truly intelligent systems. That’s exactly what we’ve built with our expanded platform.
Tecton’s platform expansion builds upon our core strengths in feature engineering and management for predictive ML. The result is a unified architecture that seamlessly supports both traditional ML and generative AI workflows.
Imagine a world where every interaction with a business feels deeply personal and intelligent, as if you’re conversing with a trusted advisor who truly knows you. With the right context and personalization, companies can evolve from mere service providers to indispensable partners in their customers’ lives. A cryptocurrency exchange transforms into a comprehensive digital asset advisor, a symptom-tracking app becomes a proactive health companion, and a payment platform evolves into an intelligent financial assistant.
This shift isn’t just about convenience; it’s about forging deeper, more meaningful relationships with customers. By leveraging AI and rich contextual data, businesses can transcend their current limitations, offering value propositions that address higher-order needs and aspirations. This transformation represents not just an incremental improvement, but a fundamental reimagining of how companies can show up for their customers, unlocking unprecedented levels of trust, engagement, and value creation.
With Tecton, we’re not just providing a platform; we’re providing the modular tools to take your AI applications to the next level with less effort and fewer resources. You don’t need an army of data engineers constantly wrangling features, embeddings, and prompts. Instead, you can focus on building incredible, personalized AI experiences that truly understand your business and your customers.