How Tecton’s Feature Platform Supercharged HomeToGo’s Ranking



This post was originally published on the HomeToGo blog and can be viewed here.
At HomeToGo, our vision is to make incredible homes easily accessible to everyone. As the SaaS-enabled marketplace with the world’s largest selection of vacation rentals, we rely heavily on advanced machine learning models to provide personalised recommendations and optimise search results. Ensuring these models have access to high-quality, reliable data in (near to) real-time is crucial to delivering a superior user experience. This is where Tecton, our feature platform, comes into play.
What is a feature store/feature platform?
Much has been written about this topic already, so piggybacking on elaborate treatments of this question, a feature platform in the context of this post refers to
A tool to serve and aggregate feature data for machine learning models at low latency. It also ensures the data’s integrity and correctness across training and production environments.
Ranking setup within HomeToGo:
- Elasticsearch: Elasticsearch is our primary search engine, responsible for indexing, searching and filtering our vast database of vacation rental listings
- Snowplow: Snowplow is used for comprehensive event tracking, capturing user interactions and behaviors across our platform. It is one of the primary sources for the data warehouse
- Snowbridge: Small service for replicate or route streams, it connects to kinesis and has multiple configurable sinks such as http endpoint
- Snowflake: Snowflake serves as our central data warehouse, storing both historical and real-time data. It also integrates seamlessly with Tecton using Snowbridge for managing feature data
- HomeToGo Search Service: Our custom ranking service applies machine learning models to the retrieved listings and determines their order based on relevance and user preferences. It encapsulates Prescoring and Rescoring models and also has its own in memory database for slowly changing features. We update once a day and this helps to serve requests in low latency
- Prescoring: The Prescoring step assigns initial score for all inventory before filtering. Prescoring runs in a batch pipeline, with the results written to elasticsearch. The Prescoring step assigns initial score for all inventory before filtering. Prescoring runs in a batch pipeline, with the results written to Elasticsearch. The scores will be used in selecting candidates to rank combined with various filters related to user selection. scores will be used in selecting candidates to rank combined with various filters related to user selection.
- Rescoring: Rescoring builds the final ranked list after filtering
Features in the Ranking Pipeline
On a high level our structure looks like this
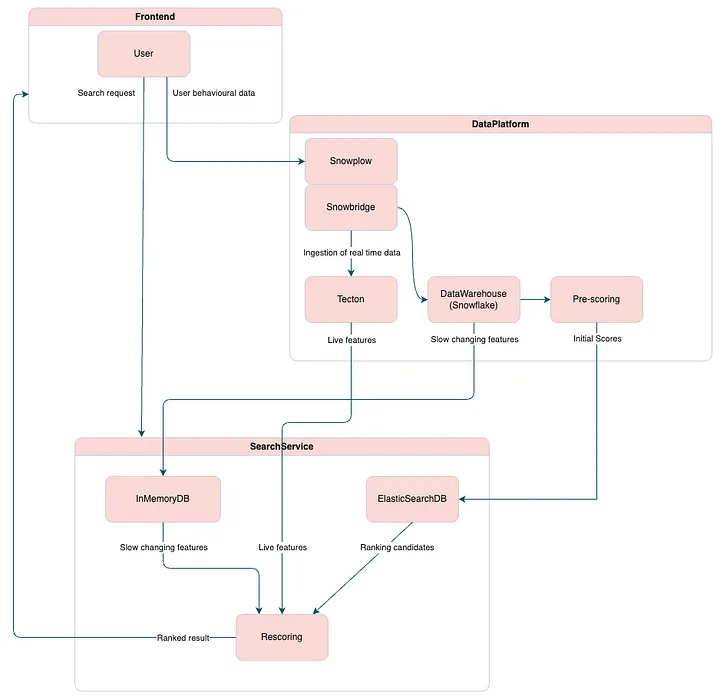
In the past, features in the ranking pipeline at HomeToGo were broadly categorised into two groups:
Offline Features
- Definition: These features change slowly and can be computed at regular intervals, typically daily, within the data warehouse (DWH) before being exported to the live ranking service.
- Examples: Offer features, provider-level features, and derived features computed over multi-week time windows.
Request time features:
- Definition: These features are available only at request time within the search service.
- Examples: User search parameters such as desired check-in durations, locations, and number of bedrooms. Additionally, transformations based on these parameters can be created.
However, this classification revealed a significant gap between offline and request time features. This gap pertains to live features.
Live Features
- Definition: Features that depend on recent history, ranging from a few seconds to a couple of hours.
- Challenges: These features were previously troublesome to handle due to their intermediate nature, yet they are crucial for personalizing the user experience and identifying high-value users.
- Importance: They play a vital role in enhancing personalization and improving the overall user experience by offering more timely and relevant data points.
By addressing this gap with our current technology stack, including Tecton and Snowbridge, we can now efficiently manage and utilise these live features, ensuring a more responsive and personalised service for our users.
Tecton setup:
To establish our feature platform, we utilized Tecton Rift, Tecton’s managed Python compute engine. This setup allowed us to manage the features entirely in Python, eliminating the need for a Spark backend. Additionally, Tecton’s integration with Snowflake, available since the end of last year, further simplified the process of incorporating Tecton into our existing stack.
Snowflake serves as our data warehouse (DWH), providing all offline data sources for Tecton, while Tecton efficiently manages and serves these data sources, ensuring point-in-time correctness and seamless data access.
Snowplow’s Snowbridge allows us to stream parts of our live event-tracking data directly to Tecton using the stream ingest API. This involves a small amount of JavaScript code to select the events to be streamed to Tecton, however all feature transformations are written in Python within Tecton.
By leveraging Tecton Rift and Snowbridge, we streamline our feature management pipeline, enhancing the real-time capabilities and overall efficiency of our machine learning infrastructure.
Example feature: Clicks_by_user_24h:
After giving a high level overview of our setup, we want to use this and walk through a short (fictional) example of setting up a single feature, total clicks by a given user over the last 24 hours.
Ingestion setup
Batch Source
Therefore we start by defining two data sources, a batch and a streaming source to combine them into a single feature.
We start with the BatchSource: This is a straightforward Snowflake connection, defining access information as well as the query to retrieve the click information we are interested in.
from tecton import BatchSource,SnowflakeConfig
# Configure BatchSource with the Snowflake Config
# SDK Reference: https://docs.tecton.ai/docs/beta/sdk-reference/data-sources/tecton.BatchSource
click_batch_source_config = SnowflakeConfig(
url="https://xyz.snowflakecomputing.com/",
database="TECTON_SERVICE",
role="TECTON_SERVICE",
schema="TEST",
warehouse="SERVE",
query=("SELECT EVENT_ID, EVENT_TIMESTAMP, USER_ID FROM TECTON_SERVICE.TECTON_INGEST.CLICK_BATCH"),
timestamp_field="EVENT_TIMESTAMP"
)
clicks_batch_source = BatchSource(
name="clicks_batch",
description="Returns click events.",
batch_config=click_batch_source_config,
owner="example@example.com"
)Live Source
To define our live source, we leverage Tecton’s Stream ingest API.
Stream ingestion API really simplifies data ingestion as it provides you HTTPs endpoint where you can submit your data in json format, this opens many integration options.
from tecton import PushSource
from tecton.types import String, Timestamp, Field, Float64
from snowflake import clicks_batch_source, click_batch_source_config
input_schema = [
Field(name="EVENT_ID", dtype=String),
Field(name="EVENT_TIMESTAMP", dtype=Timestamp),
Field(name="USER_ID", dtype=String),
]
clicks_event_source = PushSource(
batch_config=click_batch_source_config,
name="click_event_source",
schema=input_schema,
description="A push source for synchronous, online ingestion of click events."
)Snowbridge configuration
In the Snowbridge configuration we will use HTTP endpoint output connected to the user behavior stream in kinesis. It will send user events to Tecton push source.
Full configuration documentation can be found here.
source {
use "kinesis" {
stream_name = "enriched-user-events"
region = "us-west-1"
app_name = "snowbridge-tecton"
start_timestamp = "2020-01-01 10:00:00"
}
}
# Use only conversion events from snowplow in this stream
transform {
use "spEnrichedFilter" {
atomic_field = "event_name"
regex = "^(event-conversion)$"
filter_action = "keep"
}
}
# Send events to HTTP endpoint
target {
use "http" {
url = "${env.TECTON_ENDPOINT_URL}"
content_type = "application/json"
headers = "{\"Authorization\": \"Tecton-key ${env.TECTON_API_KEY}\"}"
}
}
# For transformation and second level filtering we will use javascript
transform {
use "js" {
script_path = env.JS_SCRIPT_PATH
snowplow_mode = true
}
}And in order to transform the event to the Tecton push source accepted format, we need a filter.js:
function main(input) {
// Validate input and check for required event type
if (!input?.Data || input.Data.event !== "unstruct") {
return { FilterOut: true };
}
// Extract click event details
const clickEvent = extractclickEvent(input.Data);
if (!clickEvent) {
return { FilterOut: true };
}
// Create and return the new record acording to schema
return {
Data: {
workspace_name: "prod",
dry_run: false,
records: {
click_event_source: [
{
record: {
TIMESTAMP: input.Data.collector_tstamp || null,
EVENT_ID: input.Data.event_id || null,
USER_ID: input.Data.userid
}
}
]
}
}
};
}In addition to this real time configuration, you also will need to route the same events to the Snowflake table mentioned above in the batch source — but we will skip how to do that in this example.
How to define a feature
This code defines how to construct the feature value, any aggregation or simple transformation can be defined in function in pure python. Entity will be used to define what join keys feature will use.
from datetime import datetime, timedelta
from tecton.types import Timestamp, String, Field
from tecton import Entity
from tecton import stream_feature_view, Aggregation
user = Entity(
name="user",
join_keys=["USER_ID"],
)
output_schema = [
Field(name="EVENT_TIMESTAMP", dtype=Timestamp),
Field(name="EVENT_ID", dtype=String),
Field(name="USER_ID", dtype=String),
]
@stream_feature_view(
name="user_clicks",
source=clicks_event_source,
entities=[user],
schema=output_schema,
alert_email="example@example.com",
aggregations=[
Aggregation(
column="EVENT_ID",
function="count",
time_window=timedelta(days=7),
name="clicks_24h_count",
),
]
)
def user_clicks(df):
return dfFinal step is using FeatureService to expose API endpoint for our feature view. Note:you can have multiple feature views in one service.
from tecton import FeatureService
service = FeatureService(
name="user_clicks_service",
features=[user_clicks]
)And now a similar workflow to the terraform: we just need to run the command tecton plan to see if the changes made in Tecton are what we expect and apply them.
$ tecton plan
Using workspace "prod" on cluster https://xyz.tecton.ai
✅ Imported 1 Python module from the feature repository
✅ Imported 1 Python module from the feature repository
⚠ Running Tests: No tests found.
✅ Collecting local feature declarations
✅ Performing server-side feature validation: Initializing.
↓↓↓↓↓↓↓↓↓↓↓↓ Plan Start ↓↓↓↓↓↓↓↓↓↓
+ Create Batch Data Source
name: clicks_batch
owner: example@example.com
description: Returns click events.
+ Create Stream Data Source
name: click_event_source
description: A push source for synchronous, online ingestion of click events.
+ Create Entity
name: user
+ Create Transformation
name: user_clicks
+ Create Stream Feature View
name: user_clicks
+ Create Feature Service
name: user_clicks_service
↑↑↑↑↑↑↑↑↑↑↑↑ Plan End ↑↑↑↑↑↑↑↑↑↑↑↑
Generated plan ID is 047f7116739a4f2685bb466360ea4e40
View your plan in the Web UI:
https://xyz.tecton.ai/app/prod/plan-summary/047f7116739a4f2685bb466360ea4e40
$ tecton applyUsing workspace “prod” on cluster https://xyz.tecton.aiAfter deployment in the web UI, we can see the whole flow of data visualised.
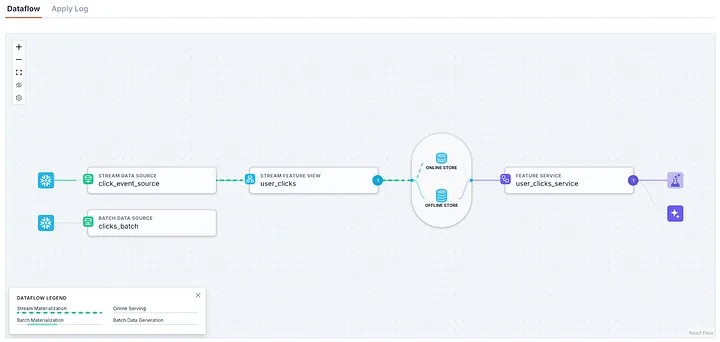
Next we need to wait for the materialisation to complete, so we can retrieve them.
And now, we can retrieve our clicks count from our new feature service endpoint by providing a join key for the user.
curl -X POST https://xyz.tecton.ai/api/v1/feature-service/get-features \
-H "Authorization: Tecton-key $TECTON_API_KEY" -d\
'{
"params": {
"feature_service_name": "user_clicks_service",
"join_key_map": {
"USER_ID": "7b521a14-e2a2-4cb3-a798-efe34e99077a"
},
"workspace_name": "prod"
}
}'Wondering how to get features for our model training? In our training notebook, we will use get historical features
import tecton
from xgboost import XGBClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
workspace = tecton.get_workspace("prod")
service = workspace.get_feature_service("user_clicks_service")
records = [
{
"USER_ID": test_user_id,
"TIMESTAMP": base_timestamp,
}
]
# Spine is on what we will join the features it shoud contain columns for timestamp and the join keys
spine = pd.DataFrame(records)
training_df = service.get_features_for_events(spine).to_pandas()
# Now you can use dataframe as usual
X = dataset[:,0:1]
Y = dataset[:,1]
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=0.3, random_state=32)
model = XGBClassifier()
model.fit(X_train, y_train)
y_pred = model.predict(X_test)from xgboost import XGBClassifierConclusion
The implementation of a feature store using Tecton marks an important step forward for HomeToGo’s ranking system. This technology enhances our ability to integrate live data into machine learning models, which helps us improve the accuracy and timeliness of our recommendations. As we continue to develop this system, we expect to make notable progress in delivering more personalised, real-time results — thereby improving user engagement and satisfaction.
The integration of Tecton with our existing tools, like Snowplow and Snowflake, has allowed us to efficiently set up this feature platform without requiring extensive resources in terms of engineering hours. By leveraging these existing systems, we were able to quickly start developing and refining our machine learning models, allowing our Data Science and Engineering teams to focus on creating more innovative solutions for vacation rental recommendations.
Looking ahead, Tecton provides a great foundation for scaling and refining our services. As HomeToGo continues on our impressive growth journey, the ability to quickly integrate new features into our models will be crucial for staying competitive in a fast-changing market.
A big shoutout goes to Audrius Rudalevicius and Stephan Kaltenstadler for setting up the feature platform and for writing this article!