Building a Feature Store


As more and more teams seek to institutionalize machine learning, we’ve seen a huge rise in ML Platform Teams who are responsible for building or buying the tools needed to enable practitioners to efficiently build production ML systems.
Almost every team tasked with building an ML platform ends up needing a feature store solution. Many teams don’t even realize that what they need is a “feature store” so to speak, but they do know that managing the data pipelines needed to fuel their ML models is the biggest barrier to getting ML models into production.
Tecton was built by a whole bunch of people who built feature stores in their past lives – from Uber’s Michelangelo to Twitter, Google, AirBnB, and more. This blog aims to help teams that are considering building a feature store by sharing some of the key challenges and decisions you’ll need to make while designing your solution.
Why do you need a feature store?
Why do you want to build a feature store in the first place? Four things we hear the most:
- You need a way to serve features to your models in real time for inference at high scale and low latency
- You want to standardize how feature pipelines are built for new ML use cases
- You don’t want to maintain separate data pipelines for training and serving, and want to reduce training / serving skew for served models
- You want your data scientists to be able to share the features they’ve built across the organization
Which of these are your top priorities will be hugely influential in the system you design! For most teams, “you need a way to serve features to your models in real time for inference” is the key challenge that drives the need for a feature store right now.
Gathering Requirements
No good project is complete without a sense of your requirements. Here are the key requirements you should collect:
| What batch data sources do you need to read raw data from | Snowflake, Redshift, S3, GCS, HDFS, … |
| What real-time data sources do you need to read raw data from | Kinesis, Kafka, Pub/Sub, RDS, … |
| What platforms does your data team use to write feature transformation logic | Snowflake, Redshift, Spark (EMR / Databricks), local python, DBT |
| How fresh do your features need to be for the use cases you are supporting | <100 ms, <1 second, <1 minute, <1 hour, <1 day, … |
| What are the latency constraints of the use cases you are supporting | P(99) / Median -<10 ms, <100ms, <1 s, batch, … |
| What is the expected serving load for the use cases you are supporting | XXX QPS |
| How many users do you plan to support? | <10, <100, 100+ |
| Will your feature store handle sensitive or regulated data assets? | Yes / No |
| Will your team need to provide an oncall engineer to support the feature store? | Yes / No |
| What is your uptime requirement? | 99%, 99.9%, 99.99%, … |
Additionally, there are a lot of optional enhancements you will likely get asked about that you’ll need to decide to build or hold off on:
- Feature Versioning
- Data lineage (including integrations with data lineage systems)
- Data Quality Monitoring
- Automatic time travel capabilities
- CI/CD capabilities for managing the deployment of features
- Cost visibility into ML data pipelines
And finally there is a whole suite of tooling that you may need to support and maintain for your feature store:
- Operational monitoring
- Canary capabilities
And with all projects it is vital to be forward thinking — the most common story we hear from teams who have built internal feature stores is that their solution worked great for use case #1 and #2, but then use case #3 came along and had different requirements (e.g. a more demanding p(99) lookup latency). Having to rearchitect your system (for example choosing completely new underlying technologies) in response to a single use case is an expensive oversight. This is always a delicate balance – you also don’t want to prematurely optimize your system for all eventualities that may never come to pass.
Understanding the Components
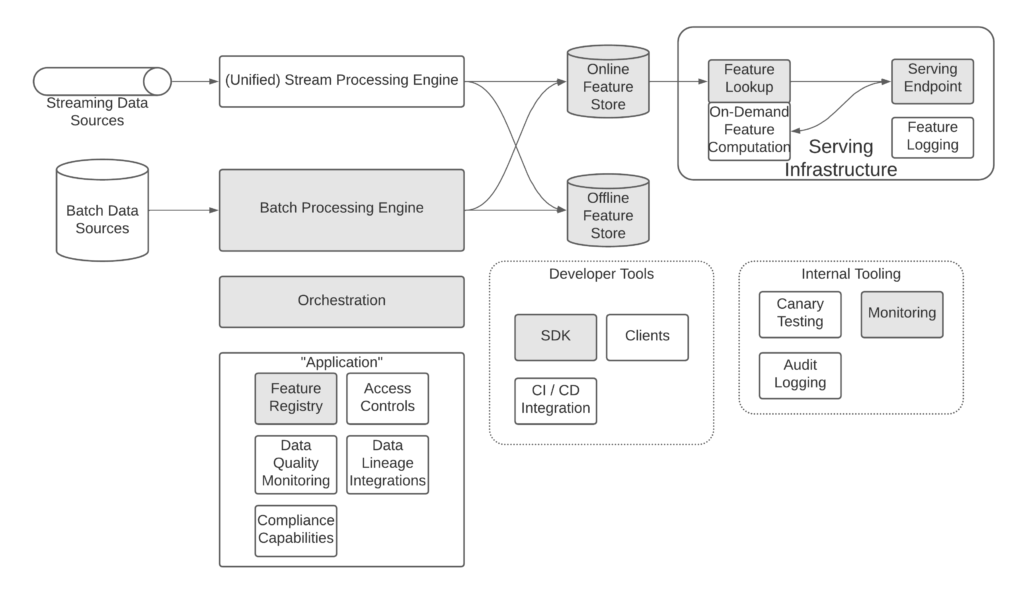
Here’s my template for the components of a feature store. The pieces that are shaded are essential for most MVPs – without a solution for each of these components you likely will not be able to drive any adoption. We’ll cover the key considerations for each of the most important components in the section below.
The build
We would need to write a whole book to do a full technical deep dive on each of the components described above, so instead we’ll focus on some of the key things to look out for when designing key components.
Overall Considerations
First, overall best practices to consider throughout the process of building a feature store:
- Even with your own build, you don’t need to manage all of the infrastructure. Look for opportunities to use managed services for critical infrastructure — tools like DynamoDB can be a lifesaver compared to managing your own infrastructure.
- When you don’t use a managed service, try to find a well established open-source project. No need to reinvent the wheel when there are communities supporting some of the key building blocks.
There is a frequent tension in this space between future proofing and premature optimization. In the data space tools evolve quickly — if you don’t future proof you could end up with an obsolete feature store in less than 12 months, but you can’t engineer for every possibility.
Feature Registry
Key dependencies: data processing engine, offline feature store, bath data sources, orchestration, CI/CD integration, access controls
Key Considerations
- We recommend building on top of Feast as an underlying feature registry. Feast is a widely used open source feature store, with a mature registry component that should serve as a solid foundation for your product.
- The feature registry is in many ways the core of a feature store. To be confident in how features are created and registered, you need to have a full understanding of the tools your team will use to store and process data. This is one of the key places to consider future proofing — we’ve talked to many teams who have had to completely reinvent their registry because of a change in their data platform (like adopting Snowflake for example!).
- If you plan to do real-time ML, your features will directly impact your production application. You’ll want a way to integrate features into the CI/CD pipelines used elsewhere in your team to roll out production software — this likely means you’ll want features to be defined as declarative code assets.
- There is an inherent tension between access controls and feature discoverability and re-use. You’ll either want to design a solution custom engineered to how your team wants to strike that balance, or you’ll need to build a system flexible enough to handle multiple possible scenarios.
Data Processing Engine (Batch and/or Streaming)
Key Dependencies: feature freshness requirements, batch data sources, streaming data sources, offline feature store, online feature store, size of data
Key Considerations:
- Once again, you’ll need to decide how much to future proof your compute engine. If you use Spark today but transition to Snowflake next year, will you need to rebuild your processing framework? At the very least you should build a plan for how your framework will generalize to new technologies.
- Users will have different requests for how they want to define feature transformation logic — data scientists will want to write Pandas code, analysts will expect to write SQL, ML engineers might expect to use Spark in Scala. You’ll need to decide between flexibility (which will take a huge engineering effort to implement) and prescriptiveness (which will reduce adoption of your feature store). We recommend erring on the side of prescriptiveness — we’ve seen over and over again that people will adapt to the tools that work as long as you provide a reliable path to production. That doesn’t mean you won’t hear complaints, but that’s better than missing deadlines.
- If you need to process streaming data, you’ll need to figure out how to do backfills. At Tecton we’ve implemented unified streaming / batch pipelines to ensure that the same logic is used to process streaming data and historical data – you’ll likely need to do the same, or else you’ll open yourself up to issues with training / serving skew. We chose to use Spark for our unified processing, but Flink and ksqlDB are other popular choices used by many teams.
- If you have a large enough scale, you may be able to cut out backfilling altogether by leveraging feature logging. Many of the largest companies in the world (Google, Twitter, …) rely almost exclusively on logging. If you’re lucky enough to operate at that scale, then backfilling is probably not worth your time.
- In general when processing streaming data, there are a lot of places where processing can fail or costs can explode in common but counter-intuitive scenarios. This is normal, but it’s good to be aware of some common issues. One of the more common examples is aggregations — one possible solution is a tiling approach.
- Your data engine will be one of the primary infrastructure costs in your solution. To help reduce costs, you may want to build support for Spot Instances, which in many cases will save you up to 50% in processing costs.
Orchestration
Key Dependencies: Data processing engine, feature registry
Key Considerations:
- There are several orchestration solutions available (like Airflow, Dagster), but most analysts and data scientists aren’t comfortable with these tools. You may need to figure out an abstraction layer (via the feature registry) that makes these tools easier to work with for the narrow scope of feature pipelines.
- Alternatively, you can build your own orchestrator to ensure it is as simple as possible for your users to interact with. This is obviously much more expensive and will take a good amount of engineering effort.
Offline Feature Store
Key Dependencies: Batch data sources, orchestration engine, SDK, compliance capabilities
Key Considerations:
- How you architect the data in your offline store will have a significant impact on the performance of your SDK for generating training data.
- You can even consider not having an offline store at all, and instead only storing the transformation logic needed to compute features. This will result in slower training data generation, but if you infrequently re-use a feature it could be cost efficient.
- You’ll likely want to match the storage location of your batch data sources — if you’ve settled on a central data strategy, your feature store should store data in that same central location.
- The same caveats as data sources apply here — if your company migrates to the cloud, you should make sure that your offline store code will be easily adapted to the new solution.
Online Feature Store
Key Dependencies: latency constraints, expected serving load, expected total data volume, cost sensitivity
Key Considerations:
- The defacto standard for online feature stores is some sort of NoSQL database like Redis, DynamoDB, Cassandra or others. These systems typically have excellent tail latencies and are optimized for very high write loads, making them an ideal choice for a high-volume application.
- Which solution you choose will depend on the constraints of your use cases. Managed services like DynamoDB are simple to use but can be extremely expensive for high QPS. Redis is extremely performant, but will require some manual management.
- Make sure you scope out more than a single use case when choosing an online store — having to migrate online stores is one of the most common stories we hear, as more demanding use cases surface.
- In particular, look out for ranking and recommendations. These use cases are often much more demanding on the online store, needing to retrieve features for thousands of candidates for each prediction. This can lead to requirements that are an order of magnitude more demanding than other use cases in your application.
Serving Infrastructure
Key Dependencies: online feature store, latency constraints, expected serving load, expected total data volume, cost sensitivity
Key Considerations:
- Having clients directly consume from the online store tightly couples your feature consumers to your infrastructure, and can make it challenging to deploy upgrades. You’ll want to build an endpoint that exposes real-time feature data centrally for your ML applications.
- You will likely do some last-minute computation at feature-serving time, like joining together multiple features to form a feature vector or computing request-time features. These capabilities can be very challenging to implement efficiently — make sure to budget a healthy chunk of engineering time to build a scalable, efficient execution engine on your serving infrastructure.
Access Controls
Key Dependencies: batch data sources, stream processing engine, feature registry, offline feature store, online feature store, feature serving infrastructure
Key Considerations:
- Access controls for feature stores are tricky, and can get in the way of realizing your goals of being able to freely share features across your organization. Depending on your use cases, everything from raw data to feature definitions to feature data could be considered sensitive and subject to access controls.
Compliance Capabilities (i.e. GDPR)
Key Dependencies: offline feature store, online feature store
Key Considerations:
- Probably the largest consideration here is how you plan to architect your offline feature store. If you plan to hold sensitive and regulated data in the feature store, you probably want to use a format like Delta Lake or another large-scale offline storage technology that supports efficient single-row deletions. You should figure this out up front to avoid an expensive migration.
SDK
Key Dependencies: Offline feature store, data scientist preferences
Key Considerations:
- Data scientists often prefer to work in iPython notebooks — you should design a simple mechanism for them to prototype features and retrieve data from a standard Python environment. Depending on where your data is stored, this can be very challenging and may require you to kick off asynchronous jobs to process large volumes of data.
Monitoring
Key Dependencies: online feature store, serving infrastructure, computation engine
Key Considerations:
- You’ll need to outfit nearly every piece of the critical inference path with monitoring capabilities to successfully support the SLAs you need to provide. To be able to scale as quickly as your team, this monitoring needs to be deployed automatically, so you’ll want to design tooling that automatically plugs into monitoring. Some common failures that you’ll want to catch are:
- Job failures when computing features
- Features becoming stale (either from stale jobs or issues with upstream data)
- Serving infrastructure underprovisioning
- High serving latencies
Canary Testing
Key Dependencies: computation engine
Key Considerations:
- Part of the promise of a feature store is consistency – feature logic should remain steady through time. If you plan to update, or even just upgrade, your computation engine (which is likely to happen as you improve the framework), you’ll want a mechanism to test that the features computed are the same before and after the changes you make. This is a challenging piece to get right, so make sure you budget necessary engineering time for it.
Key Takeaways… and a few more tips
Let’s quickly recap some of the most important takeaways:
- Future Proof vs. Premature Optimization: There are going to be a ton of places where you’ll need to decide if you want to architect a flexible (but complicated) solution, or build something that just works (for now). Follow the 80/20 rule in general – make sure what you’re building will solve for one or two key use cases to start, then expand to other use cases that fit well enough.
- Hidden Challenges: Most teams start building a feature store without realizing the full scope of what they need to build. Some of the most common mandatory components that are overlooked: monitoring, serving infrastructure, orchestration and compliance.
- Draw the line: You will be tempted to build a lot of components – some teams have gone as far as developing their own database technologies to support the online store. When in doubt, use pre-built components – in particular we recommend Feast, Managed Online Stores (like DynamoDB, Redis Enterprise), and pretty much every cloud native service that makes sense.
And finally, a few final pieces of advice about managing a feature store:
- Invest in training and onboarding: you expect most of the tools you buy to have great documentation and training tools, you need to provide the same quality of documentation and training for the tools you build.
- Plan for maintenance: We’ve worked with dozens of teams that have built feature stores, and none of them have had less than 3 full time engineers dedicated to maintaining the project. Any software this complex will require a significant amount of ongoing support.
If you’re still with us after this (admittedly daunting) blog post, best of luck! Building a feature store is challenging and exciting work – if you’re anything like me you’ll go home with a headache after many long days thinking about temporal joins. Join our slack community and talk about your experience, we love hearing from builders like yourselves!