Optimizing Feature Materialization Costs in a CI/CD Environment


Productionizing features as code with CI/CD can help organizations address new machine learning use cases or improve existing ones. Adding new features to production without the proper testing can break entire systems, but maintaining multiple feature store copies to develop and test can become very costly very fast as data sources and features scale.
At Tecton, we’ve been helping developers navigate this by establishing some best practices and even product features to ensure that you are bringing new features online in the most performant and cost effective ways possible.
Experimenting with new features
There are several common implementation strategies that may be a good fit for feature development. In this article we are going to focus on one such strategy, a GitHub Flow. In a GitHub Flow, a main branch always contains production code, and other branches can be created to add or fix features.
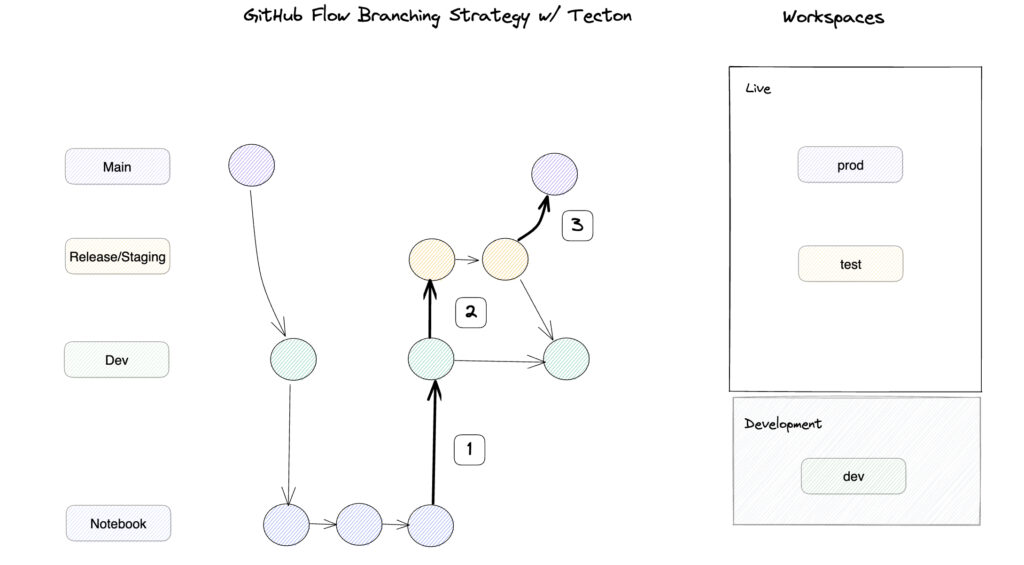
Experimentation on new features and data sources for ML can happen in a notebook. After successfully identifying a promising new feature in a notebook, it can be added to a fork of the production code, a dev branch (1 in the picture above). Features can be promoted further, to a staging environment (2), where they are incorporated into full ML pipelines before joining the features in production (3).
Continuous feature development with Tecton
In Tecton, new branches are associated with new workspaces. Running tecton apply on a branch in a new workspace creates a clone of a production environment. Tecton development workspaces are a great way to save on infrastructure costs (as they incur no costs) because they do not materialize any data and do not consume compute or serving resources, but they do ensure Tecton can effectively reach the appropriate data sources needed and the joins, aggregations, and transformations that are defined are executing as expected.
git branch checkout -b user/add-order-feature
tecton workspace create user/add-order-featureview-dev
tecton plan
tecton apply New data sources, feature views, and feature services can be interactively developed in a notebook. Once tested and verified, they can be committed to this new branch with git add and applied to the development workspace, can be promoted to a staging branch and workspace, and finally merged back into the main branch.
git add -A
git commit -m 'order feature view'
git push --set-upstream origin user/add-order-featureview-dev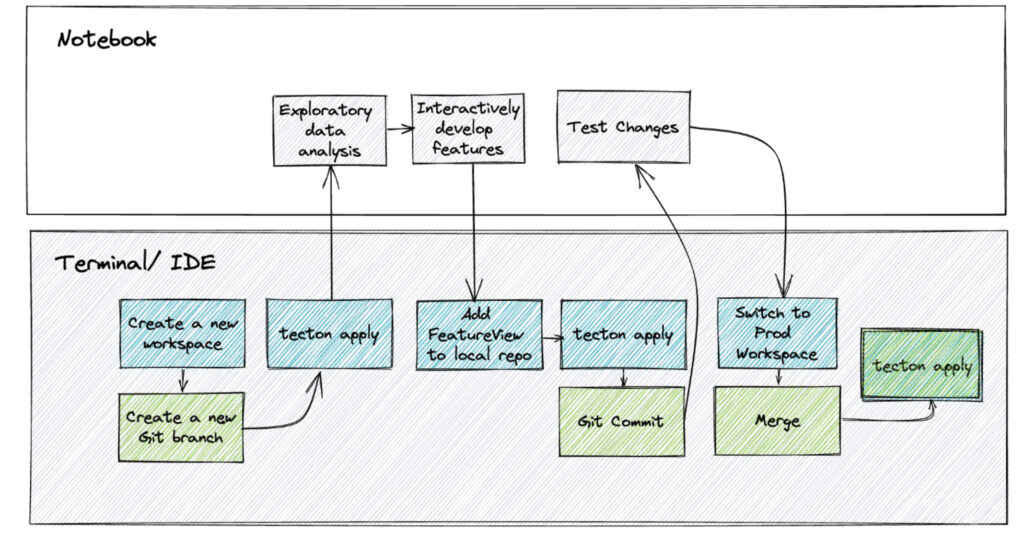
Regardless of how you experiment with feature development, further testing is still going to be needed to ensure features are integrated properly with the rest of the ML pipeline components before promoting features to production.
Promoting features to production
A testing/staging environment is where features are typically materialized in offline and online stores for the first time. Promoting feature views and feature services to a staging environment before production ensures that machine learning models can retrieve features from an offline store with a high enough throughput for model training and from an online store with a low enough latency for real-time predictions. A staging environment with Tecton provides a quick and cost effective way to make sure a full feature pipeline is working as intended via a live workspace.
git branch checkout -b user/add-order-feature
# a --live workspace will materialize features to offline and online stores
tecton workspace create user/add-order-featureview-test --live
tecton plan
tecton apply
git add -A
git commit -m 'order feature view'
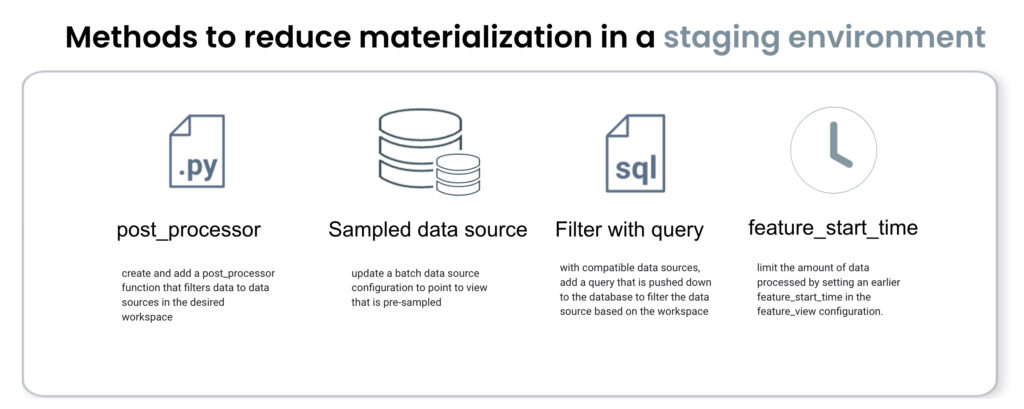
git push --set-upstream origin user/add-order-featureview-testA backfill refers to any materialization operations performed on data in the past. If features are built from data sources with large amounts of historical data, performing a full backfill in a staging environment can lead to large and unnecessary infrastructure costs. Tecton has identified 4 ways developers limit data materialized to staging environments, with Tecton’s post_processor function, reading from a sampled data source, filtering in SQL, or via Tecton’s feature_start_time. A Tecton feature view or service can have online = False to prevent unnecessary materialization to a staging environment until one of these methods has been adopted.
Once a feature is materializing properly in a staging environment, extra options can be included to facilitate a great production environment for Tecton features. Tecton automatically applies tags to resources that can be used to track their associated cloud infrastructure costs. A prevent_destroy tag can be applied to Tecton resources in production that must be unset before they can be deleted in order to prevent the need to re-materialize accidentally deleted production feature services. For a full list of the considerations and improvements that can be made when running Tecton in production, see our docs.
Trying it yourself
We have prepared a notebook to work with Tecton across dev/test/prod environments with the help of Tecton’s get_workspace and get_current_workspace functions.
from tecton import get_current_workspace
PROD_WORKSPACE = "prod"
DEV_START_TIME = datetime(2023,1,1)
def get_feature_start_time_for_env(feature_start_time):
return feature_start_time if get_current_workspace() == PROD_WORKSPACE else DEV_START_TIME
@batch_feature_view(
sources=[orders],
entities=[customer],
feature_start_time=get_feature_start_time_for_env(datetime(2018, 1, 1)),
...If you have Databricks and Tecton accounts (sign up for a free Tecton trial here), you will be able to walk through the creation and utilization of multiple Tecton workspaces to create cost effective continuous development pipelines. For ease of use, this example has been compiled into a single notebook without integrating with any Git tools, but we would recommend separating these environments by connecting Tecton to a CI/CD tool.