Put Hugging Face Embeddings Into Production With Tecton



Embeddings have proven to be some of the most important features used in machine learning, enabling machine learning algorithms to learn efficient representations of complex data. Many embeddings, in particular embeddings of audio, text or images, are computed with complex (and computationally expensive) deep learning models like transformers.
Although embeddings are incredibly powerful and versatile, working with them can be extremely challenging — you need to build complex machine learning (ML) models for your company’s raw data, generate these compute-intensive features, and make them available to your downstream models. Fortunately, Hugging Face makes this simple by providing a public repository of countless transformers that can turn your unstructured data, particularly text, into embeddings. Tecton solves the other pieces of the problem by automatically calculating these embeddings and consistently serving them for ML training and real-time predictions.
In this blog, we’ll show you how you can build an embedding feature in Tecton using Hugging Face. You’ll see how easy it is to compute document embeddings as new data arrives and use those embeddings to build downstream models.
Using embeddings for product recommendations
Let’s imagine we’re building an e-commerce site, and we want to make product recommendations to our users. This sounds like a great opportunity to use embeddings—when a new product is listed, we can generate an embedding from the product description and use that embedding to train our recommendation models:
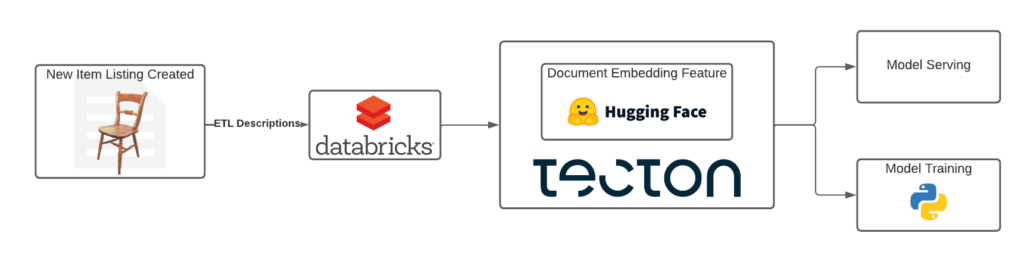
The key challenge here is building the system that will automatically compute document embeddings for each of the new listings created. Unlike with most features, it will be costly to generate these embeddings ad hoc, so it’s vital that we have a system that automatically materializes the embeddings. Luckily, Tecton makes this straightforward! Let’s see how this feature looks in Tecton, then break it down part-by-part:
def sentence_embedding(df):
import numpy as np
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('sentence-transformers/paraphrase-MiniLM-L6-v2')
contents = [d.contents for idx, d in df.iterrows()]
def chunks(lst, n):
"""Yield successive n-sized chunks from lst."""
for i in range(0, len(lst), n):
yield lst[i:i + n]
batch_size = 20
embedding_chunks = []
for c in chunks(contents, batch_size):
embeddings = model.encode(c)
embedding_chunks.append(embeddings)
embeddings = np.concatenate(embedding_chunks)
return df[['document_id', 'created_at']].assign(document_embedding=list(embeddings))
@batch_feature_view(
inputs={'documents': Input(document_data_source)},
entities=[document],
mode='pyspark',
online=True,
offline=True,
feature_start_time=datetime(2021, 12, 20),
batch_schedule='1d',
ttl='120d',
backfill_config=BackfillConfig("multiple_batch_schedule_intervals_per_job"),
description='Sentiment score of a document',
timestamp_key='created_at',
batch_cluster_config=DatabricksClusterConfig(
instance_type = 'm5.2xlarge',
instance_availability = 'on_demand',
number_of_workers = 4,
extra_pip_dependencies=["sentence-transformers", "transformers", "torch"]
)
)
def document_embedding(documents):
from pyspark.sql.types import StructType, StructField, TimestampType, ArrayType, LongType, DoubleType
from pyspark.sql.functions import spark_partition_id
label_schema = StructType(
[
StructField("document_id", LongType(), True),
StructField("document_embedding", ArrayType(DoubleType()), True),
StructField("created_at", TimestampType(), True)
]
)
documents = documents.repartition(32) #vcpus
return (
documents
.groupBy(spark_partition_id().alias("_pid"))
.applyInPandas(sentence_embedding, label_schema)
)Breaking it down
Model inference
def sentence_embedding(df):The first thing we’re going to do is build a User-Defined Function (UDF) that will invoke our document embedding model. In this case, we’ll use a pretrained sentence embedding model from our friends at Hugging Face:
SentenceTransformer('sentence-transformers/paraphrase-MiniLM-L6-v2')The rest of the UDF is straightforward: It batches sentences together, passes them through the model, and stores the embeddings. For more information about the inference process, check out the documentation for the model.
Tecton Feature View
def document_embedding(documents):
from pyspark.sql.types import StructType, StructField, TimestampType, ArrayType, LongType, DoubleType
from pyspark.sql.functions import spark_partition_id
label_schema = StructType(
[
StructField("document_id", LongType(), True),
StructField("document_embedding", ArrayType(DoubleType()), True),
StructField("created_at", TimestampType(), True)
]
)
documents = documents.repartition(32) #vcpus
return (
documents
.groupBy(spark_partition_id().alias("_pid"))
.applyInPandas(sentence_embedding, label_schema)
)The remaining feature code simply invokes our UDF on the input data (the descriptions of new products). Note that we take care to evenly distribute the data to each of our executors in Spark, making sure we take full advantage of the parallelism provided by using Spark.
@batch_feature_view(
inputs={'documents': Input(document_data_source)},
entities=[document],
mode='pyspark',
online=True,
offline=True,
feature_start_time=datetime(2021, 12, 20),
batch_schedule='1d',
ttl='120d',
description='Embedding of a document, provided by https://huggingface.co/sentence-transformers/paraphrase-MiniLM-L6-v2',
timestamp_key='created_at',
batch_cluster_config=DatabricksClusterConfig(
instance_type = 'm5.2xlarge',
instance_availability = 'on_demand',
number_of_workers = 4,
extra_pip_dependencies=["sentence-transformers", "transformers", "torch"]
)
)Finally we wrap everything up in a Tecton Feature View, used to stand up the computation pipeline needed to keep these embeddings up to date. In this case, our code instructs Tecton to orchestrate a daily job that processes all of the new listings created in the last day and calculates the embeddings of their descriptions.
Now we simply push the feature to Tecton with the CLI, and Tecton will kick off all the jobs needed to materialize (and even backfill) all of the embeddings for every product.
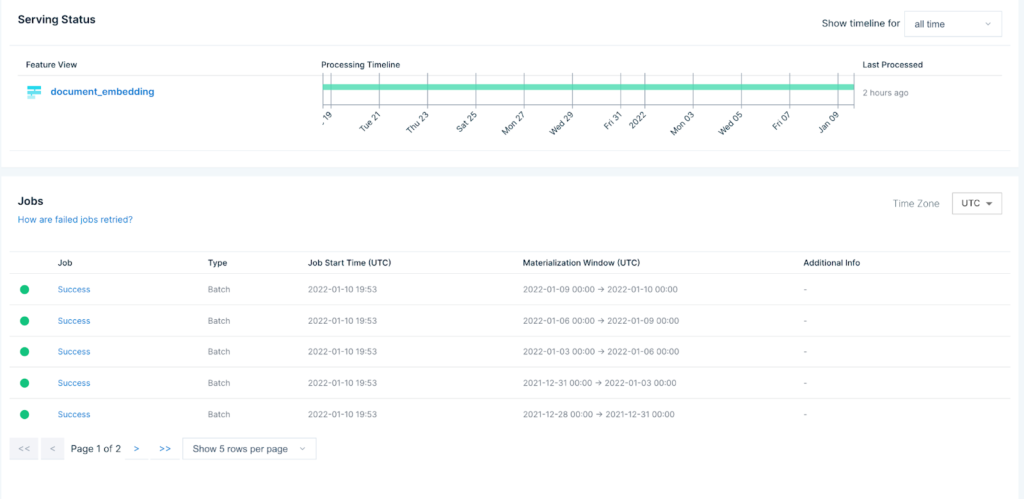
When those jobs complete, we can start using the product embeddings to build new models. You can consume them as training data for a new model:
fv = tecton.get_feature_view("document_embedding")
today = datetime.now()
yesterday = today - timedelta(days=1)
fv.get_historical_features(start_time=yesterday, end_time=today, from_source=False)And you can consume them in real time with the feature-serving API:
curl -X POST https://app.tecton.ai/api/v1/feature-service/get-features\
-H "Authorization: Tecton-key $TECTON_API_KEY" -d\
'{
"params": {
"feature_service_name": "recommendations_feature_service",
"join_key_map": {
"document_id": "document_1"
}
}
}'Conclusion
Some features are simple and can be expressed with a SQL statement. Others, like embeddings generated by transformer models, require complex logic, model artifacts, and orchestration to keep features up to date. In this article, we’ve shown how you can put Hugging Face embeddings into production easily with Tecton, and use these features to build downstream models. Whatever you’re building, Tecton is a powerful framework for expressing data pipelines that can make even the most complex feature engineering tasks simple. Check it out!
As a Senior Solutions Architect, David helped data teams build production ML applications with Tecton. He holds a Master’s Degree in Computer Science from Stanford University and a Bachelor’s Degree in Aerospace Engineering from the University of Michigan.