Simplify Real-Time AI Systems with Amazon SageMaker + Tecton




Organizations are racing to demonstrate ROI from their AI initiatives, but the path to production remains challenging – especially for demanding, real-time applications.
Take fraud detection, for instance. As financial crimes continue to surge—with US fraud losses exceeding $10 billion in 2023—organizations need systems that can make split-second decisions with high accuracy.
But building such systems typically requires complex engineering work, like building scalable data pipelines, managing compute infrastructure, and implementing reliable serving systems. The challenge becomes even more complicated when moving from batch to real-time systems.
Amazon SageMaker and Tecton are simplifying the path to production AI. While SageMaker handles model building, training, and deployment, Tecton manages the entire feature lifecycle from development to serving. This combination eliminates the need for teams to manually stitch together infrastructure components, allowing them to focus on building valuable features instead of managing complex systems.
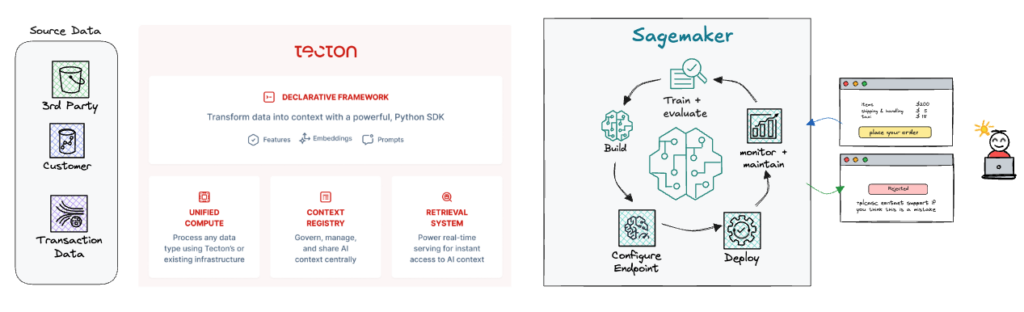
Using Tecton’s declarative framework, developers can define feature transformations in just a few lines of code, and Tecton automatically builds and manages the necessary pipelines.
This integration is particularly powerful for use cases requiring rapid response times, like recommendation engines or fraud detection systems that need to evaluate transactions in milliseconds. With Tecton + SageMaker, the end-to-end process might look like:
- Feature development: Using Tecton’s declarative framework, define features as code and generate training data in your SageMaker notebooks.
- Deployment: Tecton automatically creates the necessary data pipelines based on feature definitions.
- Real-time serving: Applications request features through Tecton’s low-latency REST API, and SageMaker endpoints consume features and return predictions.
- Ongoing management: Monitor feature pipeline health and data quality, track data lineage, and share and reuse features across multiple teams and projects.
This architecture can also extend to support generative AI applications through Amazon Bedrock, enabling teams to build sophisticated solutions that combine traditional ML with the latest language models—all using the same streamlined architecture.
Whether you’re building real-time prediction systems or GenAI applications, Tecton and SageMaker enable AI teams to build powerful real-time applications without wrestling with complex data infrastructure.
Read more about Tecton + SageMaker in the AWS Machine Learning blog.