Understanding the Feature Freshness Problem in Real-Time ML



How quickly can your ML system capture and act on recent user signals?
For time-sensitive applications like fraud detection and recommender systems, the most recent events are often the most relevant predictive signals. Like a user’s browsing activity, or a transaction made in the last few seconds.
But it’s easier said than done to get that information to your model when it’s needed.
Feature freshness is the time between when new data becomes available, and when it can be used by a model for prediction. Getting features that are freshly calculated and delivered with low latency is a complex data engineering and MLOps problem.
This post will walk through the engineering challenges of feature freshness, and then show you how HomeToGo expanded their purely batch architecture to incorporate live signals in a real-time ML system. Their new batch and streaming-enabled architecture solved their freshness needs without building any infrastructure.
What do you need for fresh features? Fresh data + fresh serving
To have fresh features for your model, you need both fresh data and fresh serving.
If you have real-time processing but you can’t leverage streaming data sources, it doesn’t matter how low-latency your system is. And if you can collect a streaming event but it takes an hour to calculate the feature, it doesn’t matter how fresh the data was.
By the time the feature is served to the model, it no longer represents the true value.
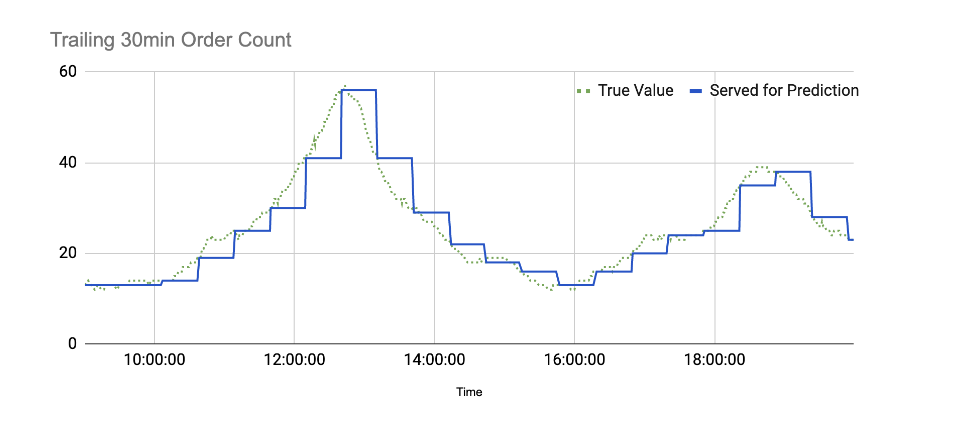
That’s why feature freshness can make or break ML apps. Stale or delayed features lead to missed fraud signals, irrelevant recommendations, and poor decisions.
It’s a complex path to get data from raw event to real-time prediction. You’ve got massive engineering challenges to address.
Challenge #1: Transforming live user data into actionable features
The first challenge is collecting and transforming timely events into ML features that can be used at inference. Features need to be calculated from live user behavior like page views and login attempts, so event-level data is necessary to make accurate predictions.
This means you’ll need to go beyond batch data and calculate features using streaming and real-time data, which introduces a new set of challenges:
- Quickly accessing a variety of data sources, from in-app search activity data to third-party fraud signals
- Getting data prepped and ready for AI model consumption
- Ensuring that the data is updated frequently and delivered in time for it to be actionable
- Handling data that arrives at unpredictable times
Many teams end up with a patchwork of stream processing systems that are difficult to monitor and prone to data loss, duplication, and skew.
Even if you build infrastructure that can process streaming and real-time data into features, you still have to solve the other challenge of serving those features quickly enough…
Challenge #2: Reducing latency between event and inference
End-to-end system delays make it difficult to accurately represent real-time events. If your ML infrastructure is slow, you’ll have a lag between when an event occurs in the real world, and when the ML system can actually “see” and process that event. How long does it take ingested data to be reflected in new reads? And how long does a read take?
Imagine a fraud detection system tracking credit card transactions. When a customer swipes their card, that event needs to crawl through a complex infrastructure maze, each step introducing latency that can compound across your stack:
- Data ingestion delays (time spent getting data from source systems into your processing pipeline)
- Processing delays (time required to transform raw events into usable features)
- State management delays: Time-window aggregations (like “sum of transactions in last hour”) must wait for late-arriving data.
The event might take minutes, hours, or even days to become observable. By then, it’s too late to stop the fraud.
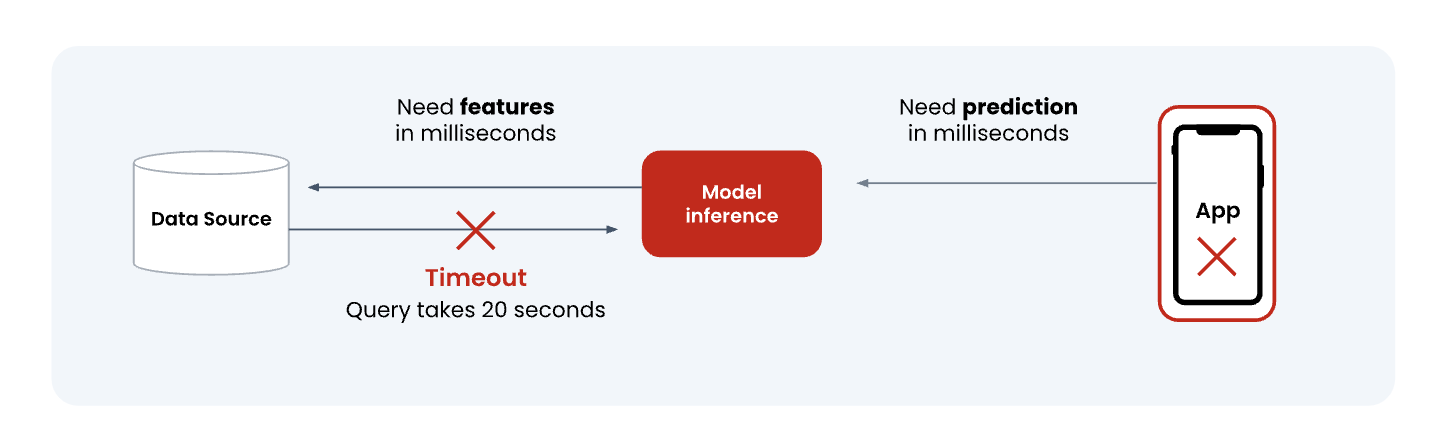
Most feature infrastructure starts with a data warehouse-based approach, designed for offline analytical use cases where staleness is tolerable. For now, your team might be okay with spending time on custom configurations to make legacy tools work.
But production, real-time ML demands a feature infrastructure that’s built for freshness.
The good news is, achieving sub-second freshness is possible without massive engineering overhead. You just need a new architectural approach.
An Architecture for Fresh Features: Real-World Example with HomeToGo
HomeToGo, the SaaS-enabled marketplace with the world’s largest selection of vacation rentals, has an ML architecture built for freshness.
HomeToGo’s search ranking system is core to their marketplace, connecting millions of users with over 20 million vacation rental offers. The ML engineering team wanted the search and ranking system to incorporate immediate user behavior, while maintaining instantaneous response times.
In a recent virtual talk, Stephan Claus, director of data analytics at HomeToGo, walked through how the ML team evolved the search ranking architecture to achieve feature freshness. Here are a few insights from their implementation:
To leverage streaming data, you shouldn’t need to spend resources building custom infrastructure.
HomeToGo started with a basic feature architecture where data came from websites and apps, and the data went into data storage (Snowflake).
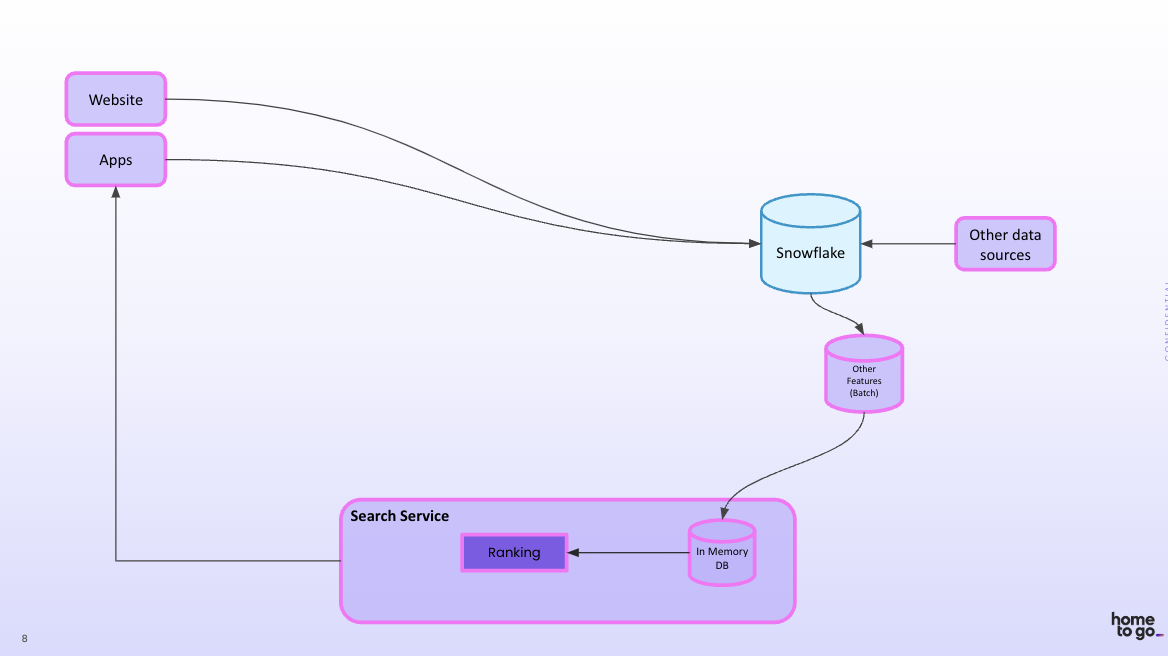
While HomeToGo had success with batch features, they saw the potential value in incorporating live user behavior – such as in-session optimization, which means taking action based on a user’s activity in their current session instead of waiting until the next day to use what was learned.
At some point, you will reach a certain performance plateau in terms of what you can optimize if you have batch features. We were thinking, is there value for us if we get these near real-time signals into the search? That’s why we started looking into solutions that we can use that don’t require us to rebuild the whole infrastructure for ourselves. Because we are aware that this is quite cumbersome. And it takes quite some engineering effort to get this into a production stable state.”
– Stephan Claus, HomeToGo
To add streaming features, HomeToGo decided they didn’t need to reinvent the wheel or build it themselves. Rather than embarking on months of custom infrastructure development, HomeToGo took a different approach.
The evolution began with Snowplow, a customer data infrastructure platform for collecting and operationalizing behavioral data. User interactions flow through Snowplow’s event streaming pipeline, where built-in schema validation ensures data quality before it enters the rest of the system. This “shift-left” approach to ensuring data quality proved crucial in a real-time environment where there’s no time to clean data after the fact.
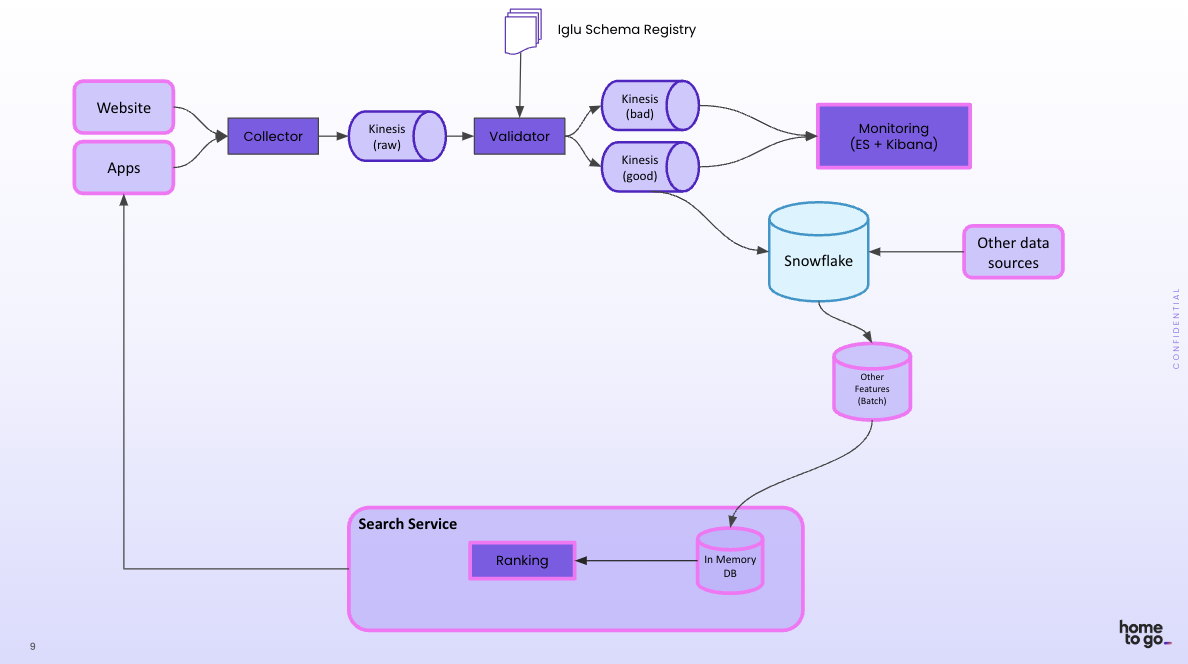
The HomeToGo team realized that their existing Snowflake and Snowplow implementation, which they’d been using since 2017, could be the foundation for a more sophisticated feature pipeline when combined with a feature platform. The right feature platform would enable them to add streaming pipelines while ensuring standardization and consistency.
HomeToGo adopted Tecton, which handles all the complex data infrastructure needed for feature computation and serving – from stream processing to online stores to monitoring.
Upgrading your ML infrastructure to accommodate streaming and real-time features would normally be a months-long deployment cycle, but using Tecton and the RIFT engine specifically, HomeToGo was able to build their new system in just a couple of weeks with a small team of two ML engineers. They can focus on testing out new features quickly and assessing value for model performance.
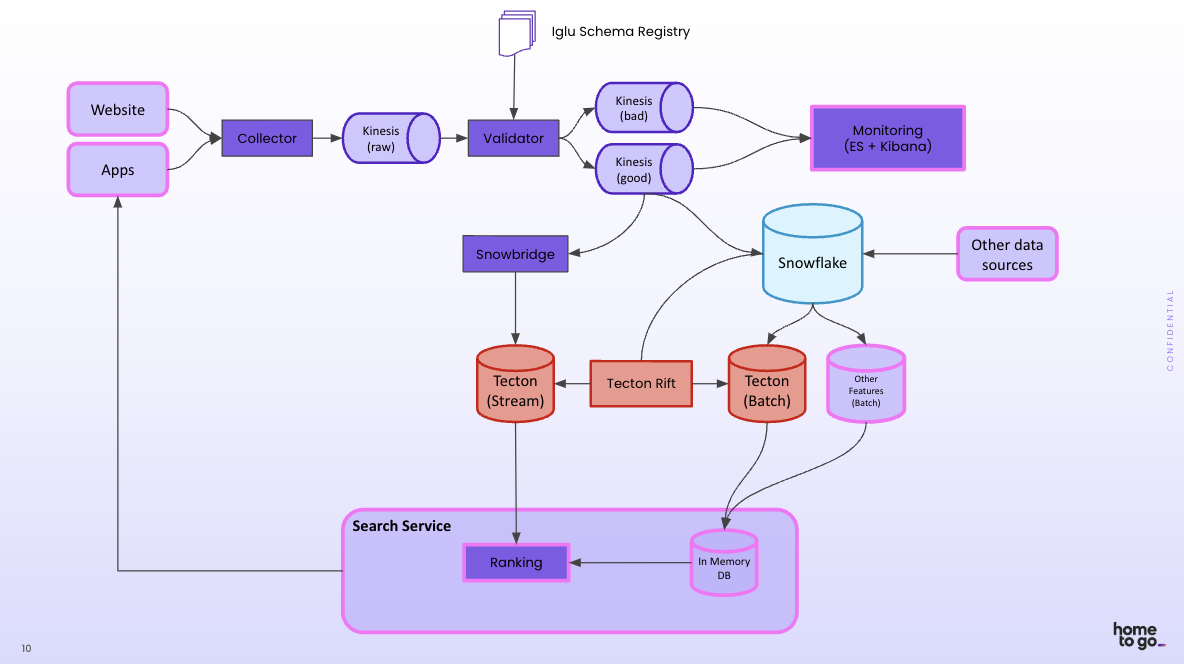
Incorporate varying levels of data freshness with a single computation framework.
Adding fresh event data means you likely need to calculate features that utilize data arriving at different times – like a combination of historical and streaming data to compute “clicks in last 7 days.”
The traditional way to do it would be building separate pipelines – perhaps a batch pipeline that performs SQL queries on historical clickstream data, and then a streaming pipeline with a custom streaming transformation job for real-time clicks. This is especially complex when the batch and streaming data cannot be trivially combined; for example, a count distinct. Here the batch and streaming need to be combined thoughtfully to produce an accurate, fresh feature.
Instead, with a unified declarative framework, HomeToGo defines the feature once as code, and the feature calculation is applied to both new streaming events and the stream’s past history of events. This ensures consistency both in real-time for predictions and offline for training, even as data arrives at different velocities.
Optimize for low latency at every possible step – accounting for both data collection and serving.
Every millisecond counts in real-time use cases like fraud detection and search ranking. As Claus noted, studies suggest that users begin to disengage when search results take longer than 250 milliseconds to load.
Features are only as fresh as the total time it takes for the feature to be served. So the latency budget in real-time ML covers every step of the process. The HomeToGo architecture reduces latency at each stage:
- Data ingestion and transformation: With an event-based pipeline design, Snowplow processes events as they arrive, avoiding the need to wait for batches.
- Real-time delivery to the feature platform: Snowplow’s Event Forwarding capability (aka Snowbridge) streams relevant events directly to Tecton at low latency.
- Feature computation: Tecton supports feature calculation with a freshness of less than 1s. HomeToGo uses Rift, Tecton’s managed compute engine, which is optimal for calculating streaming features in an event-driven architecture.
- Online serving: Tecton’s serving infrastructure can reliably run 100,000 requests per second, at a latency of << 100ms.
Your entire ML system should also be able to scale dynamically to accommodate traffic while maintaining that low latency. For instance, Claus pointed out that people might look at travel plans more on Sundays than on Wednesdays, so the system scales up and down depending on the traffic patterns.
Conclusion: The right architecture enables feature freshness without the engineering overhead.
For real-time ML use cases that power digital experiences like payments and search, the most valuable signals come from live user behavior. But pulling together all the relevant data signals quickly enough for real-time decisions – without driving up costs and engineering overhead – requires the right architecture.
Rather than building their own infrastructure, HomeToGo adopted an architecture with Tecton and Snowplow that allowed them to focus on feature design rather than the many engineering complexities that arise. To learn more about HomeToGo’s story, watch the on-demand talk here, or you can read this blog to see a more detailed example of productionizing a new feature.
And if you’re ready to start solving your own feature freshness challenge? Set up time with one of our engineers to talk through your workflow, and see how adding fresh features can be simpler than you think.


