Why AI Needs Better Context



As companies increasingly rely on AI to drive personalized, real-time decisions, the need for robust, fresh context has never been greater. When models shift from development to production, however, they often fail to perform as expected, leading to missed business opportunities and diminished user experiences. The reason? They lack comprehensive, timely context—data that captures the real-world environment and adapts to rapidly evolving patterns.
For instance, a real-time fraud detection model needs up-to-date transaction patterns, merchant risk scores, and user signals to detect suspicious activity. A customer service AI requires recent product details and a customer’s interaction history to respond accurately. Without the infrastructure to deliver fresh, structured, and unstructured data, these applications risk degrading in performance, undermining reliability in production environments.
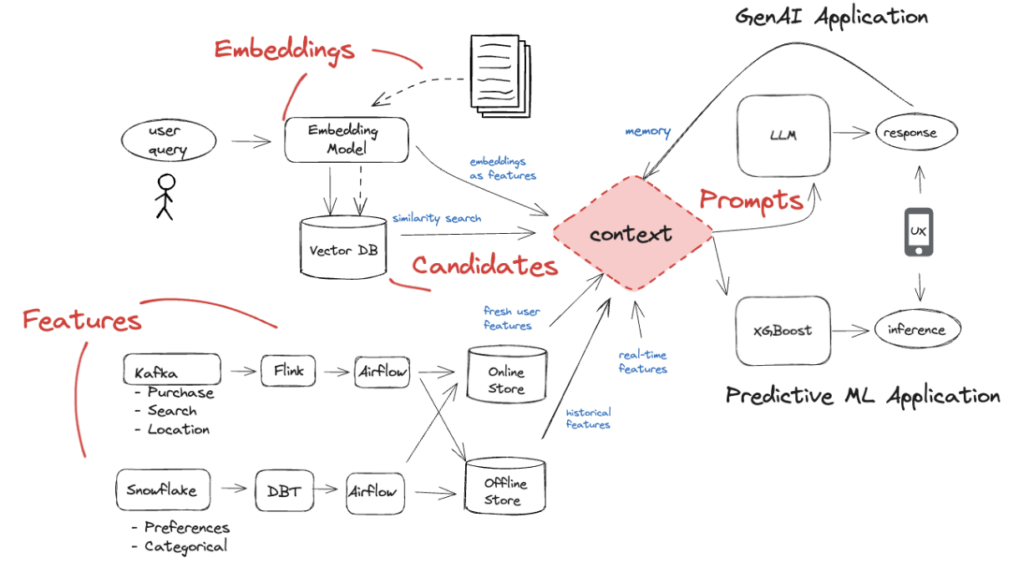
Building production-ready AI that maintains high performance requires an advanced infrastructure for delivering the right data, in the right format, with precise timing. The challenge is in seamlessly integrating and transforming multiple forms of data: structured features, embeddings for unstructured data, and dynamic prompts for large language models (LLMs). In this post, we’ll break down each form of AI context and explore what it takes to build a scalable infrastructure capable of meeting the demands of production applications.
Understanding AI Context
High-performing AI systems depend on a unified knowledge base, an infrastructure layer that combines diverse data sources into actionable context. Without this, models risk becoming outdated and irrelevant in real-world conditions, where data changes continuously. This knowledge base must synthesize structured data, semi-structured logs, and unstructured documents, orchestrating real-time, streaming, and batch data seamlessly.
For example, a customer service AI may need to pull from recent support tickets, current customer details, and real-time chat logs—retrieving this data with sub-100ms latency to deliver accurate responses. Building this infrastructure demands systems that ensure version control, reproducibility, and optimized storage, handling enormous processing loads without sacrificing performance.
Within this knowledge base, features, embeddings, and prompts serve as the pillars of AI context. Here’s why each is important—and why they’re so difficult to get right:
Features
In both predictive ML and generative AI, features provide structured signals that help models interpret specific, context-rich patterns in real-world data. For instance, in ML, features derived from batch and real-time data are crucial for applications like fraud detection and recommendation engines, capturing transaction patterns, user behavior scores, and product affinities to ensure predictions reflect current realities. In GenAI, features bring dynamic context to LLMs, helping models respond intelligently to each unique interaction—such as a support chatbot that leverages customer account status, interaction history, and recent behavior for precision in real time.
Engineering features at scale requires robust infrastructure to handle data consistency, low-latency retrieval, and seamless integration across batch, streaming, and real-time data sources—challenges that can slow down iteration cycles and increase operational complexity. To support rapid iteration, teams need systems that manage continuous updates, ensure point-in-time correctness, and automate backfilling, allowing for reliable feature reuse without the heavy engineering overhead.
Embeddings
Embeddings solve the challenge of making unstructured data computationally accessible to ML and GenAI models by transforming text, images, and audio into dense vector representations. For example, embedding transaction descriptions in fraud detection exposes patterns that may be invisible in structured data. Similarly, embeddings of product descriptions in recommendation engines facilitate a nuanced understanding of customer interests.
In LLMs, embeddings form the bridge between a model’s reasoning abilities and organization-specific data, grounding responses in unique company information, documentation, or customer interactions. Yet generating and managing embeddings in production environments is challenging. Resource-efficient embedding generation requires optimized GPU management, dynamic batching, and careful retrieval strategies. Without dedicated infrastructure, embedding processes quickly become costly and delay responses.
Prompts
For LLMs, prompts act as the dynamic instructions that define how models interact with context at inference time. These prompts bring together data from multiple sources to produce meaningful, customized outputs. In a financial advisory system, for instance, prompts combine real-time market data, individual portfolio states, and risk assessments, delivering responses tailored to specific users.
Production-scale prompt management requires an infrastructure that ensures consistency, accuracy, and performance. This means deterministic prompt construction with built-in version control and automated testing to evaluate changes reliably. With high traffic and rapid updates, LLMs demand prompt frameworks that track variations, ensure efficient token usage, and handle increasing complexity. Failing to manage prompts effectively risks both performance and relevance in production applications.
Building Production-Grade Context Infrastructure
Scaling these components into a production-ready, reliable system demands sophisticated infrastructure. At scale, companies need unified systems to coordinate features, embeddings, and prompts without sacrificing performance or increasing costs.
- Feature engineering at scale requires point-in-time accuracy across batch and streaming pipelines, with automated backfilling to ensure low-latency performance without interruptions.
- Embedding generation for production necessitates intelligent resource allocation, optimized GPU utilization, and dynamic batching to support high-volume similarity searches with sub-50ms latency.
- Prompt management, in turn, requires version control and automated testing frameworks to track prompt variations precisely, while keeping token usage efficient for scalability under high demand.
How Tecton Solves These Challenges
Tecton’s platform provides the robust infrastructure needed to compute, store, and serve dynamic AI context at scale, ensuring data freshness and reliability for both ML and GenAI applications.

For feature engineering, Tecton’s declarative framework automates the entire feature lifecycle. Engineers define transformations once, and the platform manages computation consistently across training and serving, with exactly-once processing guarantees and point-in-time accuracy. The framework orchestrates complex data pipelines, automating backfilling and supporting real-time feature serving within strict latency bounds.
In embedding generation, Tecton’s optimized engine achieves up to 15,000 embeddings per second on a single GPU, with automated resource management for cost-efficiency. Pre-configured model support allows teams to deploy high-throughput applications with minimal setup and ongoing infrastructure.
For prompt management, Tecton provides version-controlled automation for testing and performance monitoring across prompt variations, dynamically incorporating features and embeddings as needed while optimizing for token usage.
Tecton’s retrieval system ensures ultra-fast access to all context types, with intelligent caching and autoscaling to handle demand surges, maintaining 99.9% availability. The platform’s unified API enables teams to retrieve any combination of features, embeddings, and prompts seamlessly, empowering them to focus on building impactful AI applications rather than managing complex infrastructure.
Companies like Block, Plaid, and Coinbase rely on Tecton to serve millions of predictions daily with low latency and consistent accuracy. By using Tecton’s unified platform, they avoid the need to build and maintain separate systems for each context type, accelerating development timelines and allowing teams to bring smarter, more personalized AI solutions to market faster.
Want to see how all of this works in practice? Our interactive demo walks through the complete workflow, from context construction to serving, showing how Tecton makes building smarter AI faster, easier, and more cost-effective.