Why You Need a Feature Platform for Data Product Iteration



Iteration is a crucial part of any product development lifecycle and can be especially complex for data products. Momentum and appetite for iteration are crucial to the success of product teams. One of the particular challenges to iterating on a data product, however, is that even small improvements can often necessitate a large amount of both data science and production engineering effort.
That’s why it’s never too early to start setting up your ML infrastucture for iteration. While it’s tempting to wait until the first experiment read-out to start these discussions, putting the right infrastructure in place is an initial investment that will pay off across all phases of the ML iteration cycle.
In this post, I’ll focus on how a good feature platform can support the momentum and appetite to iterate on a data product while saving teams lots of time.
The machine learning iteration cycle
Before diving into how feature platforms help with iteration, let’s first take a look at what it means to iterate on a data product.
Typically, a data science team will begin with questions and observations that develop into a hypothesis. They’ll set up an experiment to test the hypothesis, launch the product, and wait for the results to bake. Whether an experiment is a success or failure, this is most likely just the beginning of the journey to develop and maintain a successful data product.
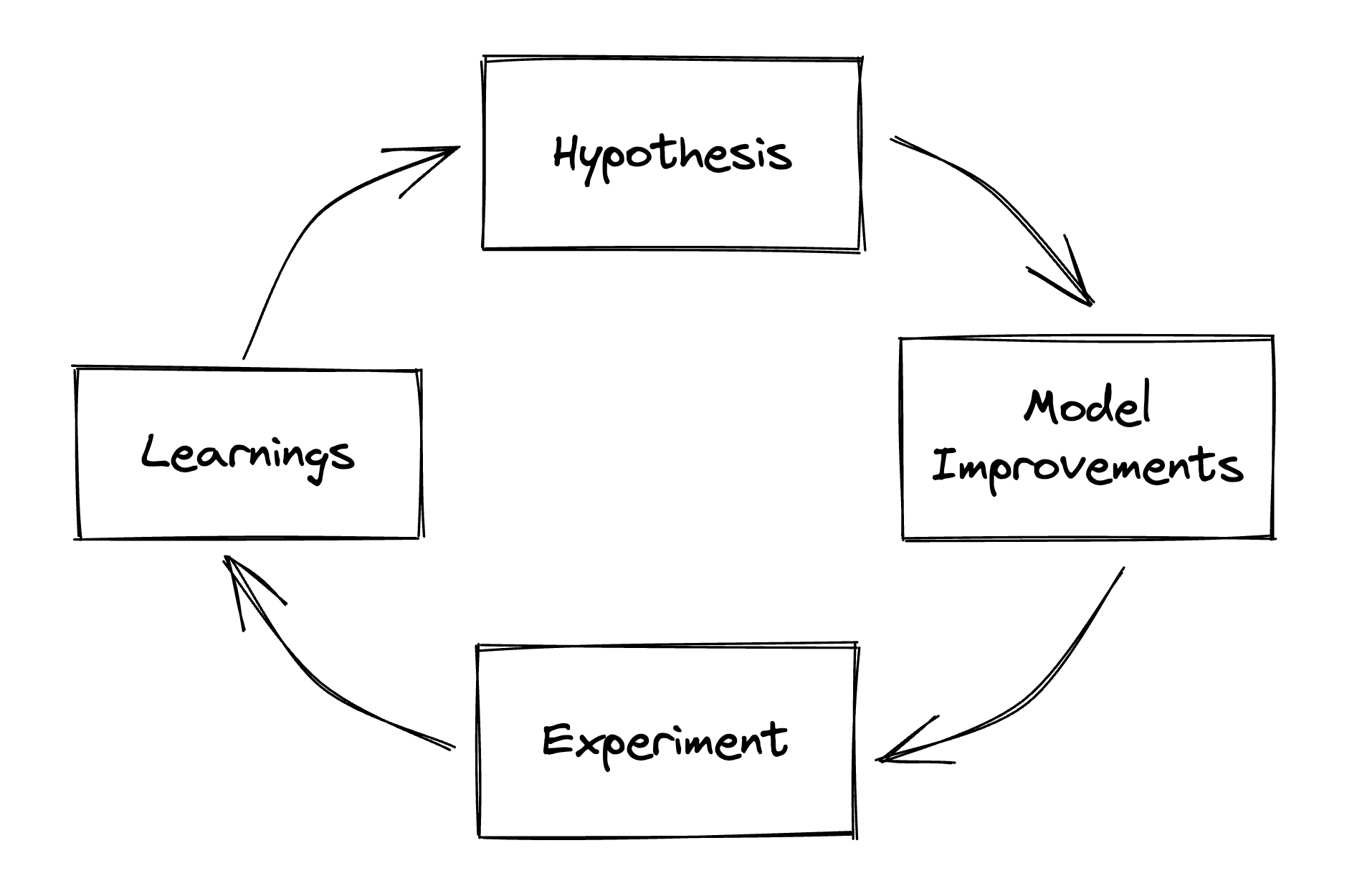
It can be difficult to pinpoint exactly how to iterate on the model without at least some initial learnings from an experiment. Although the exact next steps may vary based on the results and learning from the initial experiment, the foundation to quickly iterate and improve the model remains the same.
Why it’s important to iterate on data and features
Data products can have completely different performance even with the same model. Let’s take a quick look at why that is.
It’s because the data that’s available for prediction in online or batch inferencing is a crucial part of model performance. There are two main points that impact performance in production:
- Features should be created and used while they are still fresh and not stale. Are the features still relevant to the prediction or is the data too old?
- The time when the result of the prediction is used vs. when it was made. Is the prediction still relevant to the user?
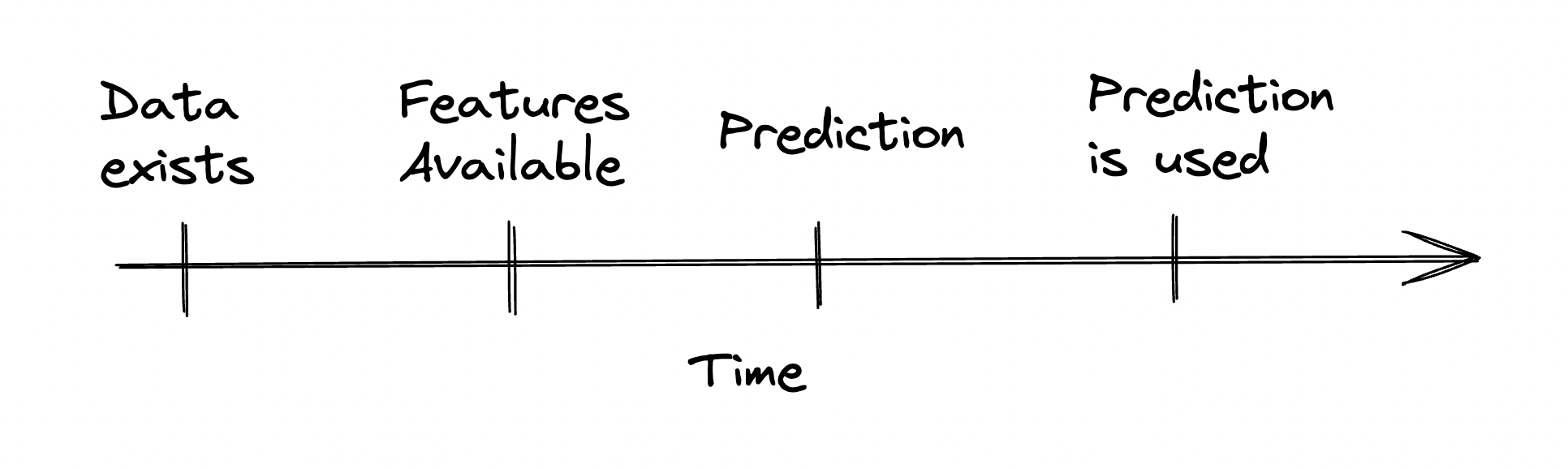
ML iteration is often about shortening the gaps in the timeline above and using experiments to prove/test whether this has a positive effect on your target metrics. Improvements might include:
- Replacing batch features with streaming and on-demand features
- Improving compute-heavy transformations and aggregates
- Improving timing of feature computation and ingestion patterns
When experimenting with different features and feature data, a feature platform can help define and version feature definitions across different environments and workspaces, as well as help iterate on feature availability.
Next, I’ll walk through how a feature platform can be used to support each of the four stages in the iteration cycle: hypothesis, model improvements, experimentation, and learnings.
1. Hypothesis
To reason through our observations and questions, it’s important to understand the current state and have a framework for what dials we have to improve that state.
A feature platform, among other capabilities, includes a catalog of features that have been developed by data scientists and are now ready to use across different environments (training, prediction, experiment analysis). As we analyze our data (observations) and try to answer some questions in a development environment, it’s helpful to be able to translate those ideas into production once we’re ready to test our hypothesis.
This feature catalog also solves the problem of data scientists “reinventing the wheel” by rebuilding a feature that already exists. Should data scientists want to create new features, a feature platform will make it easy to do declaratively (e.g., by using .py files that define existing batch, streaming, and real-time data sources).
2. Model improvements
Once we have a hypothesis we want to test, it’s time to move on to implementation. Often, the model development environment is separate from the system and infrastructure that will serve the features and predictions in production.
This leads to a common problem: When models eventually are put into production, there’s a disconnect between data scientists’ expectations and reality. That’s because production data infrastructure, such as pipelines and feature serving, will determine the following aspects of the model:
- Feature availability at the time of prediction. Are we getting feature values at all? Are we getting old feature values or fresh ones? Enhancing models with real-time features can be particularly tricky.
- Feature accuracy at the time of prediction. Was the feature transformed correctly? Are there major differences between the data the model was trained on and the data it’s seeing in production?
- Feature serving latency. Are data pipelines introducing delay in the prediction time? If this is a production model that needs to serve predictions in the product, any added latency could be unacceptable for the user experience.
A feature platform handles these issues by acting as a central engine for features, both for development and production. By using feature definitions in .py files, a feature platform orchestrates data pipelines to materialize these features in online and offline stores, making them available to production models via a simple API call.
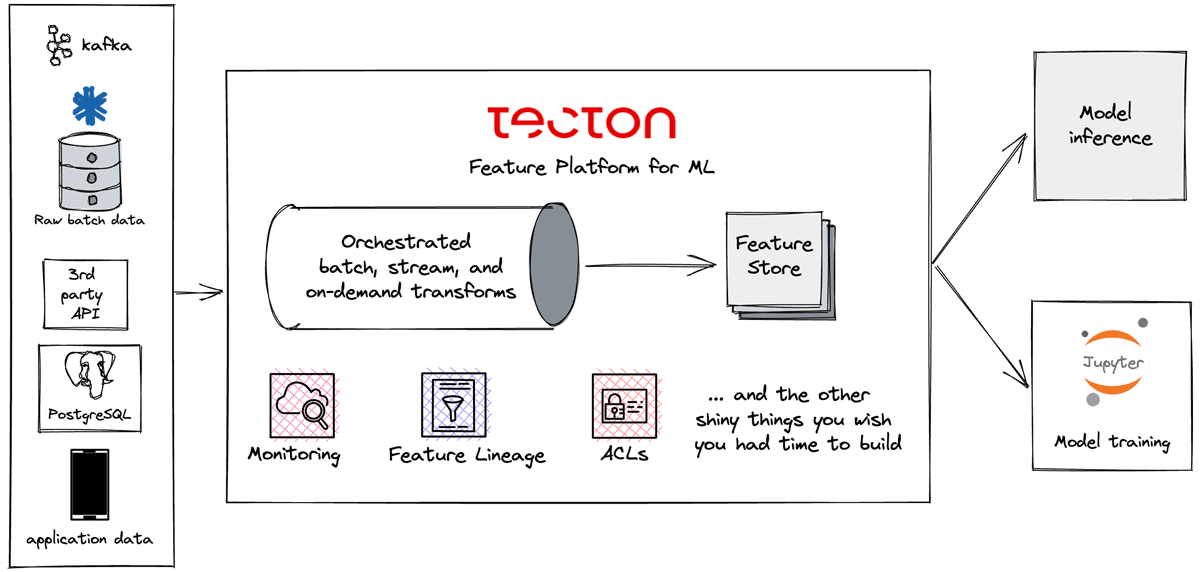
3. Experimentation
Experimentation is the backbone for understanding how a data product performs in production. It’s no secret that to develop and use models, we need good data. But having good data is not always enough for continuous experimentation. In many cases, data teams need the ability to easily transform, manage, and version that data as feature vectors that feed into models and subsequently become a part of the experiment.
Even with good experimentation infrastructure that can support continuous A/B testing, versioning is key to experimentation setups and read-outs. When we unpack or reproduce an experiment, it’s important to know the version of the model and its feature definitions. Feature definitions are a crucial part of the model version because they define a key part of the data product in our experiments. We want to be able to understand not only what features were used, but what sources and transformations those feature vectors came from.
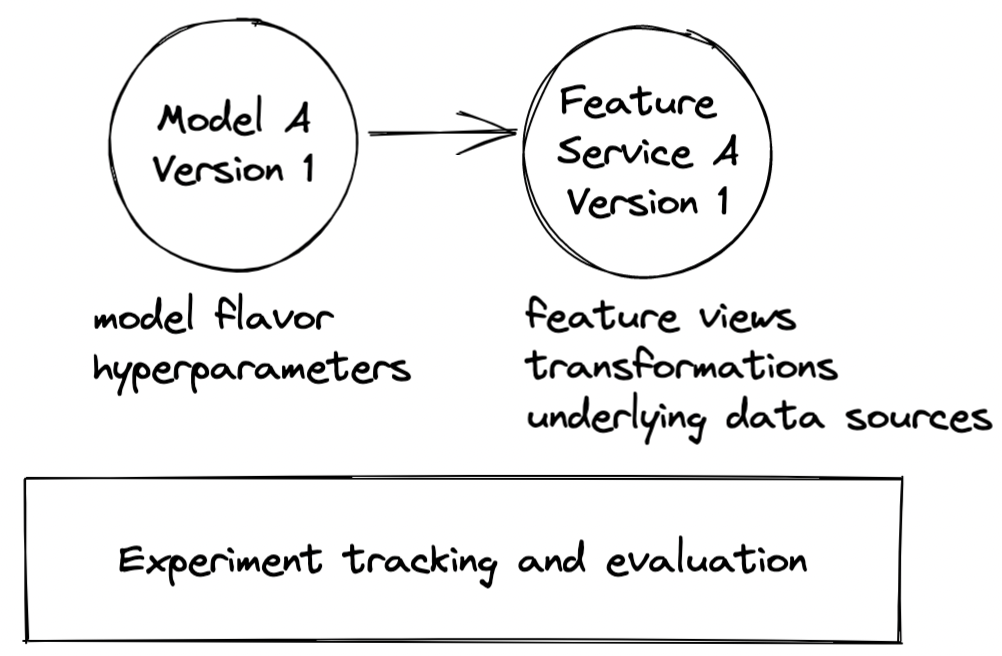
Versioning features can get complicated quickly. If the experiment was a success, the “previous” model becomes the incumbent, which means the next experiment will have 2+ different models and 2+ different feature definitions. How do we track which features are being used by which models? And what if some features have the same definition, but are materialized differently (e.g., streaming vs. batch)? How do we distinguish between them?
With a feature platform, we can manage feature definitions in code and version them appropriately as we iterate.
Example
In the toy example below, I’ll demonstrate how simple it is to use Tecton’s feature platform to define and version different feature services for multiple iterations of a data product. In this case, the product is a movie recommendations model.
In the first iteration, a simple v0 model recommends movies to existing users using pre-computed features based on an aggregate of user ratings. In the next iteration, the v1 model includes features about the user. The v2 model introduces near real-time rating features so that brand new users can also get quality recommendations after signing up.
We start by defining the data sources for the v0 approach. Here we’re using the MovieLens 25M file dataset but could also have used hive, glue, Redshift, Snowflake, etc. as data sources.
from tecton import BatchSource, FileConfig
from transformers import convert_epoch_to_timestamp
movies_file_config = FileConfig(
uri='s3://tecton-demo-data/movielens_25m/movies.csv',
file_format='csv',
)
ratings_file_config = FileConfig(
uri='s3://tecton-demo-data/movielens_25m/ratings.csv',
file_format='csv',
timestamp_field='timestamp',
post_processor=convert_epoch_to_timestamp,
)
movies = BatchSource(
name='movies',
batch_config=movies_file_config,
description='A source of movie titles and their genres',
)
ratings = BatchSource(
name='ratings',
batch_config=ratings_file_config,
description='A source of movie ratings given by users',
)Next, using a query around our data sources, we define a set of aggregate features about an average user rating for a list of movie genres.
from datetime import timedelta, datetime
from tecton import batch_feature_view, Entity, Aggregation, BatchTriggerType
from datasources import ratings, movies
user = Entity(
name='user',
join_keys=['userId'],
description='A user of the platform',
)
# defining a batch feature view to get the average customer rating per genre
def gen_preference_feature(genre):
@batch_feature_view(
name=f"user_{genre}_rating_history",
mode="spark_sql",
sources=[ratings, movies],
entities=[user],
aggregation_interval=timedelta(days=1),
# defines the aggregation functions(s) on our queried dataset
aggregations=[
Aggregation(
column='rating',
function='mean',
time_window=timedelta(days=30),
),
],
online=True,
offline=True,
description=f"Average rating user gave to {genre} movies over last 30 days",
tags={"release": "production"},
)
def fv(ratings, movies):
# query the ratings and movies data source to get the genre rating feature
return f'''
SELECT
{ratings}.userId,
CAST(rating as DOUBLE) rating,
timestamp
FROM
{ratings}
INNER JOIN {movies}
ON {ratings}.movieId = {movies}.movieId
WHERE
{movies}.genres LIKE '%{genre}%'
'''
return fv
genres = [
'Action',
'Adventure',
'Comedy',
'Horror',
'Fantasy',
'Romance',
'Drama',
]
genre_preference_features = [gen_preference_feature(genre) for genre in genres]Iteration Version 0
We define the feature service, movie_recs_feature_service, which can be used by a model to recommend movies to users. A feature service exposes features (in this case one feature view per genre), defined in a set of feature views, as an API.
from tecton import FeatureService
from batch_features import genre_preference_features
movie_feature_service = FeatureService(
name='movie_recs_feature_service',
online_serving_enabled=True,
features=genre_preference_features,
tags={"release": "production"},
)Iteration Version 1
In the next approach, we could just as simply define user data sources and define user features to add to the next version of the model and data product. We can add these new features to a new version of a feature service, while reusing the genre_preference_features
from tecton import FeatureService
from batch_features import genre_preference_features, user_profile_features
movie_feature_service = FeatureService(
name='movie_recs_feature_service',
online_serving_enabled=True,
features=genre_preference_features,
tags={"release": "production"},
)
movie_feature_service_v1 = FeatureService(
name='movie_recs_feature_service:v1',
online_serving_enabled=True,
features=genre_preference_features + [user_profile_features],
tags={"release": "production"},
)Iteration Version 2
What if we wanted to introduce personalized recommendations for users that just signed up after a brief onboarding survey? In order to have features available to predict recommendations for brand-new users, we can use on-demand or streaming feature views.
With the Tecton feature platform, we can define a new stream source.
ratings_stream = StreamSource(
name='ratings_stream',
stream_config=KinesisConfig(
stream_name='rating_events',
region='us-west-2',
post_processor=raw_stream_translator,
...
),
batch_config=rating_file_config,
)Again, using a query around our data sources, we define a new set of aggregate features, but this time we utilize the ratings_stream.
def gen_preference_stream_feature(genre):
@stream_feature_view(
name=f"user_{genre}_rating_history_stream",
mode="spark_sql",
sources=[ratings_stream, movies],
entities=[user],
aggregations=[
Aggregation(
column='rating',
function='mean',
time_window=timedelta(days=30),
),
],
online=True,
description=f”Average rating user gave to {genre} movies over last 30 days”,
tags={"release": "production"},
)
def fv(ratings, movies):
return f'''
SELECT
{ratings}.userId,
CAST(rating as DOUBLE) rating,
timestamp
FROM
{ratings}
INNER JOIN {movies}
ON {ratings}.movieId = {movies}.movieId
WHERE
{movies}.genres LIKE '%{genre}%'
'''
return fv
genres = [
'Action',
'Adventure',
'Comedy',
'Horror',
'Fantasy',
'Romance',
'Drama',
]
genre_preference_stream_features = [gen_preference_stream_feature(genre) for genre in genres]Finally, we can add another feature service version to facilitate the next iteration of this toy recommendation product.
from tecton import FeatureService
from batch_features import genre_preference_features, user_profile_features
from stream_features import genre_preference_stream_features
...
movie_feature_service_v2 = FeatureService(
name='movie_recs_feature_service:v2',
online_serving_enabled=True,
features=genre_preference_stream_features + [user_profile_features],
tags={"release": "production"},
)In this example, we define the next version of the feature service, movie_recs_feature_service:v2. We can now A/B test multiple approaches in the next iteration cycle to try to prove that this solution works for a cold-start recommendation. In the context of our iteration cycle, this can help us version the multiple approaches so that we can put our new model to the test against the initial version of the data product.
You can check out more examples in https://github.com/tecton-ai-ext/apply-workshop-2022 and https://github.com/tecton-ai-ext/tecton-sample-repo.
4. Learnings
Once the results of the experiment are solidified, the infrastructure needs to support pushing the changes into production quickly. With one source of truth for defining and versioning features that can be utilized across different environments, a feature platform makes the transition to production much easier.
A feature platform also helps you understand, measure, and improve feature availability in production. Feature definitions can be combined into feature views and services to manage the version of data sources, transformations, and feature views we’re utilizing for a specific use case. This also helps share common feature definitions across multiple models and use cases.
Key takeaways
Iteration gives us a chance to use new learnings and observations from experiments to improve and develop a successful data product. However, one of the major challenges of iterating on a data product is creating the supporting infrastructure. In this post, I shared how a feature platform helps:
- Catalog data and features so you can more easily hypothesize how to improve models.
- Manage the data and transformation pipelines for features so that you can make model improvements that will behave the same way in development and production.
- Version your features so that you can see the impact of different feature definitions and materializations on your model.
- Flip a switch in the code to push your model updates to production.
A feature platform will increase iteration velocity and empower data scientists to improve model performance since it reduces the need for engineering resources to implement and maintain complex data pipelines.
If you have questions about how a feature platform can help you iterate, reach out to us or schedule a demo of Tecton—we’d love to help!