Why You Need to Incorporate Machine Learning Into Your Search Ranking System



On e-commerce platforms and many other customer-facing applications, search result relevance is a critical factor in driving conversions and enhancing the user experience. As product inventory size grows, companies face the challenge of efficiently surfacing products that align with a user’s search intent and are most likely to result in a purchase.
Traditional search methods, such as basic keyword matching or off-the-shelf search solutions, often fail to meet users’ increasing demands. However, machine learning (ML) offers a powerful approach to improving search results by making them contextually relevant and tailored to each user.
In this article, I’ll delve into the process of building a real-time, ML–based search-and-ranking system, including how feature platforms like Tecton help teams deliver contextualized and personalized search experiences in production.
Improving search results relevance using machine learning
Let’s consider an example of a user searching for “wireless headphones” on an e-commerce website. Conventional search methods would primarily rely on keyword matching, resulting in a broad range of products containing the term “wireless headphones” without considering the user’s specific preferences.
ML can significantly enhance search result relevance by incorporating additional factors and capturing a user’s taste and intent at the time of the search. For example, the user may have demonstrated a strong preference for a particular brand by repeatedly purchasing electronics from that brand in the last few months or they might have even browsed related products just a few minutes before this specific search. This valuable information can be taken into account by an ML model to personalize and contextualize search results.
On top of users expecting their search results to be relevant and personalized, they also expect them to be returned within milliseconds. Teams implementing real-time search engines at scale face a lot of challenges, including deploying the right architecture stack to serve predictions at high scale and low latency or combining and serving fresh ML features from various sources to the ranking model. Because of this complexity, a lot of companies end up using generic off-the-shelf solutions that don’t leverage all the in-house data that’s available to make search results relevant.
That said, those who successfully implemented their own personalized and contextual search ranking like Airbnb saw significant conversion rate increases. The juice is worth the squeeze!
How to implement real-time personalized search & ranking systems in production
There are a variety of different approaches to ML-based search. However, similar to online recommendation engines, search systems are usually composed of 3 main steps:
- Candidate generation
- Feature retrieval
- Ranking model inference
In production, these steps are either done in separate microservices or in a single inference service that orchestrates the different parts of the inference pipeline. Let’s dive deeper into each of these steps.
Candidate generation
The purpose of the candidate generation step is to narrow down the number of items our ML model will need to rank (candidate space). It is especially important because the search and ranking process will happen in real time, and evaluating the relevance of every single item in our inventory within the latency budget is usually not feasible.
During candidate generation, a user’s search query is transformed into a query embedding vector using techniques like word embeddings or contextual language models. This query embedding is then compared against item embeddings which are vectorized representations of the item’s description. The goal is to identify a subset of candidate items that are close in vector space to the query embedding, indicating a higher likelihood of relevance to the user’s search intent. An efficient technique to achieve this without having to compare the query embedding with every single item vector is to use approximate nearest neighbor (ANN) search algorithms.
In practice, you could get started with open source ANN implementations like FAISS or Annoy. But while these are simple and effective solutions to get started, they require you to load the entire search index containing the item vectors in RAM, so you will run into deployment and scalability issues when running them in production.
On the other hand, vector databases like Pinecone, Pgvector for Postgres, or Redis are purpose-built to handle large-scale search applications. They offer optimized storage and indexing mechanisms that efficiently manage vector data, ensuring smooth scalability and minimizing deployment complexities.
Another benefit of using vector databases is that they can store metadata associated with each item vector (e.g., price, brand, category), which allows for heuristic-based filtering of the candidate list to further narrow down the candidate space based on business rules.
How feature platforms help with feature retrieval
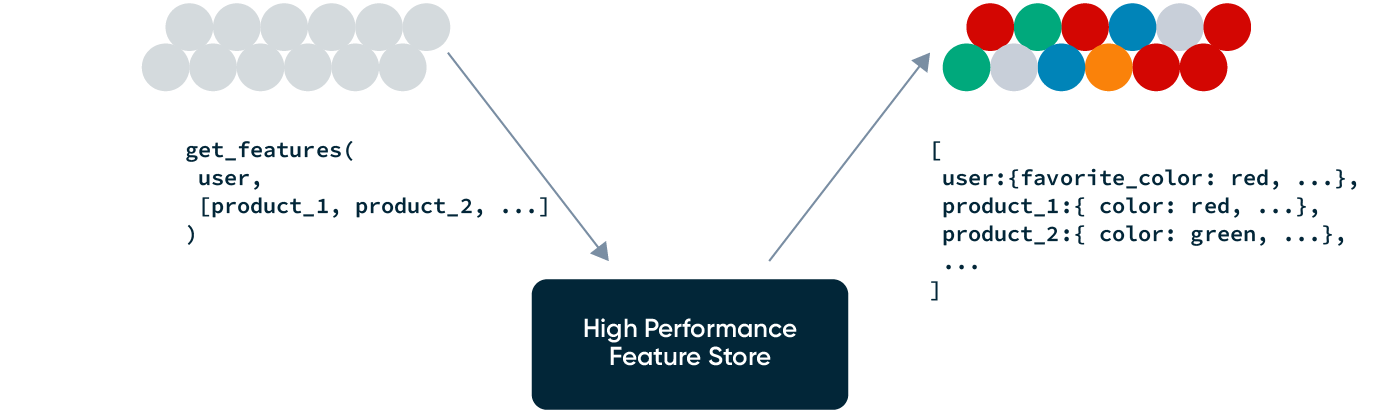
Once we’ve generated our list of candidate items, we’ll need to rank all search query—item pairs based on the item’s predicted relevance score. The relevance score is computed using a ranking model that takes query, item, and user features as inputs and outputs a relevance score for the query-item-user triplet.
Here are a few examples of useful features that are typically seen in ranking models:
Query-Item features:
- E.g., Similarity between the search query and the product title using various string/embedding distance metrics
- E.g., whether the search query contains the candidate item’s name or brand
User features:
- E.g., Last n items visited by the user in the current session (30 min)
Item features:
- E.g., Total sales, add to carts, and page visits for the candidate item in the last year
User-Item features:
- E.g., whether the candidate item has been viewed by the user in the last hour
- E.g., whether the user has purchased the candidate item in the past
While it is conceptually simple to understand how the above features could be good predictors of the item’s relevance, computing these feature values and making them available to our ranking model in real time and with the right freshness requires a lot of engineering overhead.
In the above list, some features need to be computed on-the-fly (e.g., Jaccard similarity between the search query and the product title). Other features, like long-term time window aggregates, can be pre-computed using batch data sources and refreshed every day (e.g., total item sales in the past year). Some features have very high freshness requirements (e.g., last-n items viewed by the user in the previous 30 min with second-level freshness) and need to be computed from streaming events. This requires teams to deploy, monitor, and manage batch, streaming, and real-time data processing infrastructure—which often deters teams from including powerful features in their model.
Feature platforms like Tecton help abstract away this complexity by managing and orchestrating feature engineering pipelines that continuously compute, store, and serve feature values to the ML models. From a simple repository of declarative feature definition files, Tecton automates the deployment of the data pipelines that will compute and update feature values, in addition to making them available to our models for training or inference.
Below is an example of how you can define the “Total sales, add to carts, page visits for the candidate item in the last year” feature with Tecton
from tecton import batch_feature_view, Aggregation
from datetime import datetime, timedelta
from Search.entities import product
from Search.data_sources import search_user_interactions
@batch_feature_view(
description='''Product performance metrics to capture how popular a candidate product is
based on last year visit, add to cart, purchase totals''',
sources=[search_user_interactions],
entities=[product],
mode='spark_sql',
aggregation_interval=timedelta(days=1)
aggregations=[Aggregation(column='purchase', function='sum', time_window=timedelta(days=365)),
Aggregation(column='visit', function='sum', time_window=timedelta(days=365)),
Aggregation(column='add_to_cart', function='sum', time_window=timedelta(days=365))],
batch_schedule=timedelta(days=1)
)
def product_yearly_totals(search_user_interactions):
return f"""
select
product_uid,
timestamp,
if(event='add_to_cart',1,0) as add_to_cart,
if(event='visit',1,0) as visit,
if(event='purchase',1,0) as purchase
from {search_user_interactions}
"""Once these features are pushed to Tecton, Tecton will continuously update the online feature store with fresh feature values and populate the offline store with historical feature values. We can now generate a training dataset containing point-in-time accurate feature values as well as retrieve fresh feature vectors at millisecond latency for our production models with minimal effort!
In production, our inference service will call Tecton to retrieve a feature vector for each of the search query-candidate item pairs. The feature vectors are then fed into the ranking model, which outputs a relevance score for each query-candidate item pair. Once we have the relevance score of each candidate item, candidate items can be sorted according to those scores.
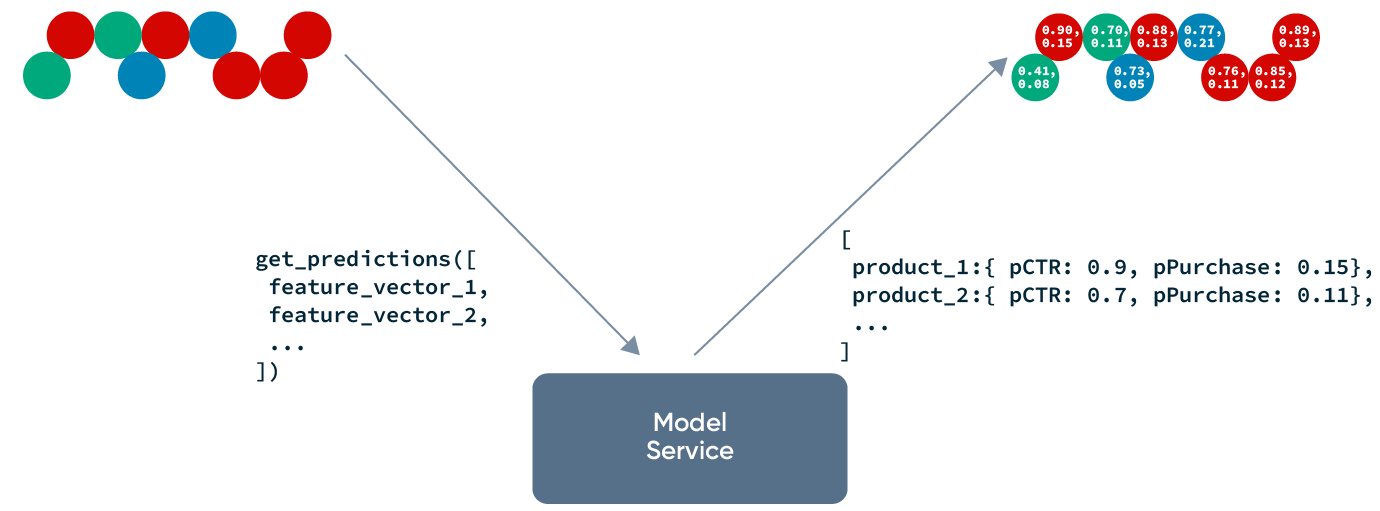
Ranking model inference

While there are specific techniques and algorithms like Learning to Rank that can be applied to ranking problems for information retrieval, your go-to pointwise ML approaches using models like XGBoost or LightGBM usually provide a strong baseline. Labels could be relevance scores that are manually annotated. This approach, however, is labor intensive and slow. Instead, labels are usually created from previous searches and downstream events that indicate a user’s implied feedback on the search results. For example, in the context of e-commerce, a good indicator of relevance is whether the user clicked on the search result or whether that search result led to a purchase.
Search queries usually follow a skewed distribution, with a small number of search queries accounting for the majority of search traffic. Teams get the best results by focusing their efforts on these popular queries when optimizing their ranking model.
In practice, once the model predicts relevance scores for each query-item pair, further business logic and filtering is applied to ensure a good balance between relevance, diversity, and availability of results.
Key Takeaways
Providing personalized search results is a great way to increase conversions and drive better user experiences. While many teams have achieved significant results by incorporating more ML in their search systems, a lot of teams are stalling because of implementation complexity. Teams have adopted feature platforms for their search-and-ranking systems so they can better:
- Leverage in-house data to model user preferences
- Compute and combine real-time, near-real-time, and batch features
- Serve feature values at high scale and low latency
- Limit the amount of engineering effort to build and deploy feature pipelines
Interested in learning more? Reach out to us for a personalized 1:1 demo.